これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
スケジューリングと退避
- 1: Node上へのPodのスケジューリング
- 2: Podのオーバーヘッド
- 3: TaintとToleration
- 4: Kubernetesのスケジューラー
- 5: スケジューラーのパフォーマンスチューニング
- 6: スケジューリングフレームワーク
1 - Node上へのPodのスケジューリング
Podが稼働するNodeを特定のものに指定したり、優先条件を指定して制限することができます。 これを実現するためにはいくつかの方法がありますが、推奨されている方法はラベルでの選択です。 スケジューラーが最適な配置を選択するため、一般的にはこのような制限は不要です(例えば、複数のPodを別々のNodeへデプロイしたり、Podを配置する際にリソースが不十分なNodeにはデプロイされないことが挙げられます)が、 SSDが搭載されているNodeにPodをデプロイしたり、同じアベイラビリティーゾーン内で通信する異なるサービスのPodを同じNodeにデプロイする等、柔軟な制御が必要なこともあります。
nodeSelector
nodeSelectorは、Nodeを選択するための、最も簡単で推奨されている手法です。
nodeSelectorはPodSpecのフィールドです。これはkey-valueペアのマップを特定します。
あるノードでPodを稼働させるためには、そのノードがラベルとして指定されたkey-valueペアを保持している必要があります(複数のラベルを保持することも可能です)。
最も一般的な使用方法は、1つのkey-valueペアを付与する方法です。
以下に、nodeSelectorの使用例を紹介します。
ステップ0: 前提条件
この例では、KubernetesのPodに関して基本的な知識を有していることと、Kubernetesクラスターのセットアップがされていることが前提となっています。
ステップ1: Nodeへのラベルの付与
kubectl get nodesで、クラスターのノードの名前を取得してください。
そして、ラベルを付与するNodeを選び、kubectl label nodes <node-name> <label-key>=<label-value>で選択したNodeにラベルを付与します。
例えば、Nodeの名前が'kubernetes-foo-node-1.c.a-robinson.internal'、付与するラベルが'disktype=ssd'の場合、kubectl label nodes kubernetes-foo-node-1.c.a-robinson.internal disktype=ssdによってラベルが付与されます。
kubectl get nodes --show-labelsによって、ノードにラベルが付与されたかを確認することができます。
また、kubectl describe node "nodename"から、そのNodeの全てのラベルを表示することもできます。
ステップ2: PodへのnodeSelectorフィールドの追加
該当のPodのconfigファイルに、nodeSelectorのセクションを追加します: 例として以下のconfigファイルを扱います:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
nodeSelectorを以下のように追加します:

apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd
kubectl apply -f https://k8s.io/examples/pods/pod-nginx.yamlにより、Podは先ほどラベルを付与したNodeへスケジュールされます。
kubectl get pods -o wideで表示される"NODE"の列から、PodがデプロイされているNodeを確認することができます。
補足: ビルトインNodeラベル
明示的に付与するラベルの他に、事前にNodeへ付与されているものもあります。 これらのラベルのリストは、Well-Known Labels, Annotations and Taintsを参照してください。
kubernetes.io/hostnameの値はNodeの名前と同じである環境もあれば、異なる環境もあります。
Nodeの隔離や制限
Nodeにラベルを付与することで、Podは特定のNodeやNodeグループにスケジュールされます。 これにより、特定のPodを、確かな隔離性や安全性、特性を持ったNodeで稼働させることができます。 この目的でラベルを使用する際に、Node上のkubeletプロセスに上書きされないラベルキーを選択することが強く推奨されています。 これは、安全性が損なわれたNodeがkubeletの認証情報をNodeのオブジェクトに設定したり、スケジューラーがそのようなNodeにデプロイすることを防ぎます。
NodeRestrictionプラグインは、kubeletがnode-restriction.kubernetes.io/プレフィックスを有するラベルの設定や上書きを防ぎます。
Nodeの隔離にラベルのプレフィックスを使用するためには、以下のようにします。
- Node authorizerを使用していることと、NodeRestriction admission pluginが 有効 になっていること。
- Nodeに
node-restriction.kubernetes.io/プレフィックスのラベルを付与し、そのラベルがnode selectorに指定されていること。 例えば、example.com.node-restriction.kubernetes.io/fips=trueまたはexample.com.node-restriction.kubernetes.io/pci-dss=trueのようなラベルです。
アフィニティとアンチアフィニティ
nodeSelectorはPodの稼働を特定のラベルが付与されたNodeに制限する最も簡単な方法です。
アフィニティ/アンチアフィニティでは、より柔軟な指定方法が提供されています。
拡張機能は以下の通りです。
- アフィニティ/アンチアフィニティという用語はとても表現豊かです。この用語は論理AND演算で作成された完全一致だけではなく、より多くのマッチングルールを提供します。
- 必須条件ではなく優先条件を指定でき、条件を満たさない場合でもPodをスケジュールさせることができます。
- Node自体のラベルではなく、Node(または他のトポロジカルドメイン)上で稼働している他のPodのラベルに対して条件を指定することができ、そのPodと同じ、または異なるドメインで稼働させることができます。
アフィニティは"Nodeアフィニティ"と"Pod間アフィニティ/アンチアフィニティ"の2種類から成ります。
NodeアフィニティはnodeSelector(前述の2つのメリットがあります)に似ていますが、Pod間アフィニティ/アンチアフィニティは、上記の3番目の機能に記載している通り、NodeのラベルではなくPodのラベルに対して制限をかけます。
Nodeアフィニティ
Nodeアフィニティは概念的には、NodeのラベルによってPodがどのNodeにスケジュールされるかを制限するnodeSelectorと同様です。
現在は2種類のNodeアフィニティがあり、requiredDuringSchedulingIgnoredDuringExecutionとpreferredDuringSchedulingIgnoredDuringExecutionです。
前者はNodeにスケジュールされるPodが条件を満たすことが必須(nodeSelectorに似ていますが、より柔軟に条件を指定できます)であり、後者は条件を指定できますが保証されるわけではなく、優先的に考慮されます。
"IgnoredDuringExecution"の意味するところは、nodeSelectorの機能と同様であり、Nodeのラベルが変更され、Podがその条件を満たさなくなった場合でも
PodはそのNodeで稼働し続けるということです。
将来的には、requiredDuringSchedulingIgnoredDuringExecutionに、PodのNodeアフィニティに記された必須要件を満たさなくなったNodeからそのPodを退避させることができる機能を備えたrequiredDuringSchedulingRequiredDuringExecutionが提供される予定です。
それぞれの使用例として、
requiredDuringSchedulingIgnoredDuringExecution は、"インテルCPUを供えたNode上でPodを稼働させる"、
preferredDuringSchedulingIgnoredDuringExecutionは、"ゾーンXYZでPodの稼働を試みますが、実現不可能な場合には他の場所で稼働させる"
といった方法が挙げられます。
Nodeアフィニティは、PodSpecのaffinityフィールドにあるnodeAffinityフィールドで特定します。
Nodeアフィニティを使用したPodの例を以下に示します:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0このNodeアフィニティでは、Podはキーがkubernetes.io/e2e-az-name、値がe2e-az1またはe2e-az2のラベルが付与されたNodeにしか配置されません。
加えて、キーがanother-node-label-key、値がanother-node-label-valueのラベルが付与されたNodeが優先されます。
この例ではオペレーターInが使われています。
Nodeアフィニティでは、In、NotIn、Exists、DoesNotExist、Gt、Ltのオペレーターが使用できます。
NotInとDoesNotExistはNodeアンチアフィニティ、またはPodを特定のNodeにスケジュールさせない場合に使われるTaintsに使用します。
nodeSelectorとnodeAffinityの両方を指定した場合、Podは両方の条件を満たすNodeにスケジュールされます。
nodeAffinity内で複数のnodeSelectorTermsを指定した場合、PodはいずれかのnodeSelectorTermsを満たしたNodeへスケジュールされます。
nodeSelectorTerms内で複数のmatchExpressionsを指定した場合にはPodは全てのmatchExpressionsを満たしたNodeへスケジュールされます。
PodがスケジュールされたNodeのラベルを削除したり変更しても、Podは削除されません。 言い換えると、アフィニティはPodをスケジュールする際にのみ考慮されます。
preferredDuringSchedulingIgnoredDuringExecution内のweightフィールドは、1から100の範囲で指定します。
全ての必要条件(リソースやRequiredDuringSchedulingアフィニティ等)を満たしたNodeに対して、スケジューラーはそのNodeがMatchExpressionsを満たした場合に、このフィルードの"weight"を加算して合計を計算します。
このスコアがNodeの他の優先機能のスコアと組み合わせれ、最も高いスコアを有したNodeが優先されます。
Pod間アフィニティとアンチアフィニティ
Pod間アフィニティとアンチアフィニティは、Nodeのラベルではなく、すでにNodeで稼働しているPodのラベルに従ってPodがスケジュールされるNodeを制限します。
このポリシーは、"XにてルールYを満たすPodがすでに稼働している場合、このPodもXで稼働させる(アンチアフィニティの場合は稼働させない)"という形式です。
Yはnamespaceのリストで指定したLabelSelectorで表されます。
Nodeと異なり、Podはnamespaceで区切られているため(それゆえPodのラベルも暗黙的にnamespaceで区切られます)、Podのラベルを指定するlabel selectorは、どのnamespaceにselectorを適用するかを指定する必要があります。
概念的に、XはNodeや、ラック、クラウドプロバイダゾーン、クラウドプロバイダのリージョン等を表すトポロジードメインです。
これらを表すためにシステムが使用するNodeラベルのキーであるtopologyKeyを使うことで、トポロジードメインを指定することができます。
先述のセクション補足: ビルトインNodeラベルにてラベルの例が紹介されています。
topologyKeyで指定されたものに合致する適切なラベルが必要になります。
それらが付与されていないNodeが存在する場合、意図しない挙動を示すことがあります。
Nodeアフィニティと同様に、PodアフィニティとPodアンチアフィニティにも必須条件と優先条件を示すrequiredDuringSchedulingIgnoredDuringExecutionとpreferredDuringSchedulingIgnoredDuringExecutionがあります。
前述のNodeアフィニティのセクションを参照してください。
requiredDuringSchedulingIgnoredDuringExecutionを指定するアフィニティの使用例は、"Service AのPodとService BのPodが密に通信する際、それらを同じゾーンで稼働させる場合"です。
また、preferredDuringSchedulingIgnoredDuringExecutionを指定するアンチアフィニティの使用例は、"ゾーンをまたいでPodのサービスを稼働させる場合"(Podの数はゾーンの数よりも多いため、必須条件を指定すると合理的ではありません)です。
Pod間アフィニティは、PodSpecのaffinityフィールド内にpodAffinityで指定し、Pod間アンチアフィニティは、podAntiAffinityで指定します。
Podアフィニティを使用したPodの例
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: k8s.gcr.io/pause:2.0
このPodのアフィニティは、PodアフィニティとPodアンチアフィニティを1つずつ定義しています。
この例では、podAffinityにrequiredDuringSchedulingIgnoredDuringExecution、podAntiAffinityにpreferredDuringSchedulingIgnoredDuringExecutionが設定されています。
Podアフィニティは、「キーが"security"、値が"S1"のラベルが付与されたPodが少なくとも1つは稼働しているNodeが同じゾーンにあれば、PodはそのNodeにスケジュールされる」という条件を指定しています(より正確には、キーが"security"、値が"S1"のラベルが付与されたPodが稼働しており、キーがtopology.kubernetes.io/zone、値がVであるNodeが少なくとも1つはある状態で、
Node Nがキーtopology.kubernetes.io/zone、値Vのラベルを持つ場合に、PodはNode Nで稼働させることができます)。
Podアンチアフィニティは、「すでにあるNode上で、キーが"security"、値が"S2"であるPodが稼働している場合に、Podを可能な限りそのNode上で稼働させない」という条件を指定しています
(topologyKeyがtopology.kubernetes.io/zoneであった場合、キーが"security"、値が"S2"であるであるPodが稼働しているゾーンと同じゾーン内のNodeにはスケジュールされなくなります)。
PodアフィニティとPodアンチアフィニティや、requiredDuringSchedulingIgnoredDuringExecutionとpreferredDuringSchedulingIgnoredDuringExecutionに関する他の使用例はデザインドックを参照してください。
PodアフィニティとPodアンチアフィニティで使用できるオペレーターは、In、NotIn、 Exists、 DoesNotExistです。
原則として、topologyKeyには任意のラベルとキーが使用できます。
しかし、パフォーマンスやセキュリティの観点から、以下の制約があります:
- アフィニティと、
requiredDuringSchedulingIgnoredDuringExecutionを指定したPodアンチアフィニティは、topologyKeyを指定しないことは許可されていません。 requiredDuringSchedulingIgnoredDuringExecutionを指定したPodアンチアフィニティでは、kubernetes.io/hostnameのtopologyKeyを制限するため、アドミッションコントローラーLimitPodHardAntiAffinityTopologyが導入されました。 トポロジーをカスタマイズする場合には、アドミッションコントローラーを修正または無効化する必要があります。preferredDuringSchedulingIgnoredDuringExecutionを指定したPodアンチアフィニティでは、topologyKeyを省略することはできません。- 上記の場合を除き、
topologyKeyは任意のラベルとキーを指定することができます。
labelSelectorとtopologyKeyに加え、labelSelectorが合致すべきnamespacesのリストを特定することも可能です(これはlabelSelectorとtopologyKeyを定義することと同等です)。
省略した場合や空の場合は、アフィニティとアンチアフィニティが定義されたPodのnamespaceがデフォルトで設定されます。
requiredDuringSchedulingIgnoredDuringExecutionが指定されたアフィニティとアンチアフィニティでは、matchExpressionsに記載された全ての条件が満たされるNodeにPodがスケジュールされます。
実際的なユースケース
Pod間アフィニティとアンチアフィニティは、ReplicaSet、StatefulSet、Deploymentなどのより高レベルなコレクションと併せて使用するとさらに有用です。 Workloadが、Node等の定義された同じトポロジーに共存させるよう、簡単に設定できます。
常に同じNodeで稼働させる場合
3つのノードから成るクラスターでは、ウェブアプリケーションはredisのようにインメモリキャッシュを保持しています。 このような場合、ウェブサーバーは可能な限りキャッシュと共存させることが望ましいです。
ラベルapp=storeを付与した3つのレプリカから成るredisのdeploymentを記述したyamlファイルを示します。
Deploymentには、1つのNodeにレプリカを共存させないためにPodAntiAffinityを付与しています。
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
ウェブサーバーのDeploymentを記載した以下のyamlファイルには、podAntiAffinity とpodAffinityが設定されています。
全てのレプリカがapp=storeのラベルが付与されたPodと同じゾーンで稼働するよう、スケジューラーに設定されます。
また、それぞれのウェブサーバーは1つのノードで稼働されないことも保証されます。
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: web-store
replicas: 3
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.16-alpine
上記2つのDeploymentが生成されると、3つのノードは以下のようになります。
| node-1 | node-2 | node-3 |
|---|---|---|
| webserver-1 | webserver-2 | webserver-3 |
| cache-1 | cache-2 | cache-3 |
このように、3つのweb-serverは期待通り自動的にキャッシュと共存しています。
kubectl get pods -o wide
出力は以下のようになります:
NAME READY STATUS RESTARTS AGE IP NODE
redis-cache-1450370735-6dzlj 1/1 Running 0 8m 10.192.4.2 kube-node-3
redis-cache-1450370735-j2j96 1/1 Running 0 8m 10.192.2.2 kube-node-1
redis-cache-1450370735-z73mh 1/1 Running 0 8m 10.192.3.1 kube-node-2
web-server-1287567482-5d4dz 1/1 Running 0 7m 10.192.2.3 kube-node-1
web-server-1287567482-6f7v5 1/1 Running 0 7m 10.192.4.3 kube-node-3
web-server-1287567482-s330j 1/1 Running 0 7m 10.192.3.2 kube-node-2
同じNodeに共存させない場合
上記の例では PodAntiAffinityをtopologyKey: "kubernetes.io/hostname"と合わせて指定することで、redisクラスター内の2つのインスタンスが同じホストにデプロイされない場合を扱いました。
同様の方法で、アンチアフィニティを用いて高可用性を実現したStatefulSetの使用例はZooKeeper tutorialを参照してください。
nodeName
nodeNameはNodeの選択を制限する最も簡単な方法ですが、制約があることからあまり使用されません。
nodeNameはPodSpecのフィールドです。
ここに値が設定されると、schedulerはそのPodを考慮しなくなり、その名前が付与されているNodeのkubeletはPodを稼働させようとします。
そのため、PodSpecにnodeNameが指定されると、上述のNodeの選択方法よりも優先されます。
nodeNameを使用することによる制約は以下の通りです:
- その名前のNodeが存在しない場合、Podは起動されす、自動的に削除される場合があります。
- その名前のNodeにPodを稼働させるためのリソースがない場合、Podの起動は失敗し、理由は例えばOutOfmemoryやOutOfcpuになります。
- クラウド上のNodeの名前は予期できず、変更される可能性があります。
nodeNameを指定したPodの設定ファイルの例を示します:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: kube-01
上記のPodはkube-01という名前のNodeで稼働します。
次の項目
Taintsを使うことで、NodeはPodを追い出すことができます。
Nodeアフィニティと Pod間アフィニティ/アンチアフィニティ のデザインドキュメントには、これらの機能の追加のバックグラウンドの情報が記載されています。
一度PodがNodeに割り当たると、kubeletはPodを起動してノード内のリソースを確保します。 トポロジーマネージャーはNodeレベルのリソース割り当てを決定する際に関与します。
2 - Podのオーバーヘッド
Kubernetes v1.18 [beta]
PodをNode上で実行する時に、Pod自身は大量のシステムリソースを消費します。これらのリソースは、Pod内のコンテナ(群)を実行するために必要なリソースとして追加されます。Podのオーバーヘッドは、コンテナの要求と制限に加えて、Podのインフラストラクチャで消費されるリソースを計算するための機能です。
Kubernetesでは、PodのRuntimeClassに関連するオーバーヘッドに応じて、アドミッション時にPodのオーバーヘッドが設定されます。
Podのオーバーヘッドを有効にした場合、Podのスケジューリング時にコンテナのリソース要求の合計に加えて、オーバーヘッドも考慮されます。同様に、Kubeletは、Podのcgroupのサイズ決定時およびPodの退役の順位付け時に、Podのオーバーヘッドを含めます。
Podのオーバーヘッドの有効化
クラスター全体でPodOverheadのフィーチャーゲートが有効になっていること(1.18時点ではデフォルトでオンになっています)と、overheadフィールドを定義するRuntimeClassが利用されていることを確認する必要があります。
使用例
Podのオーバーヘッド機能を使用するためには、overheadフィールドが定義されたRuntimeClassが必要です。例として、仮想マシンとゲストOSにPodあたり約120MiBを使用する仮想化コンテナランタイムで、次のようなRuntimeClassを定義できます。
---
kind: RuntimeClass
apiVersion: node.k8s.io/v1
metadata:
name: kata-fc
handler: kata-fc
overhead:
podFixed:
memory: "120Mi"
cpu: "250m"
kata-fcRuntimeClassハンドラーを指定して作成されたワークロードは、リソースクォータの計算や、Nodeのスケジューリング、およびPodのcgroupのサイズ決定にメモリーとCPUのオーバーヘッドが考慮されます。
次のtest-podのワークロードの例を実行するとします。
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
runtimeClassName: kata-fc
containers:
- name: busybox-ctr
image: busybox
stdin: true
tty: true
resources:
limits:
cpu: 500m
memory: 100Mi
- name: nginx-ctr
image: nginx
resources:
limits:
cpu: 1500m
memory: 100Mi
アドミッション時、RuntimeClassアドミッションコントローラーは、RuntimeClass内に記述されたオーバーヘッドを含むようにワークロードのPodSpecを更新します。もし既にPodSpec内にこのフィールドが定義済みの場合、そのPodは拒否されます。この例では、RuntimeClassの名前しか指定されていないため、アドミッションコントローラーはオーバーヘッドを含むようにPodを変更します。
RuntimeClassのアドミッションコントローラーの後、更新されたPodSpecを確認できます。
kubectl get pod test-pod -o jsonpath='{.spec.overhead}'
出力は次の通りです:
map[cpu:250m memory:120Mi]
ResourceQuotaが定義されている場合、コンテナ要求の合計とオーバーヘッドフィールドがカウントされます。
kube-schedulerが新しいPodを実行すべきNodeを決定する際、スケジューラーはそのPodのオーバーヘッドと、そのPodに対するコンテナ要求の合計を考慮します。この例だと、スケジューラーは、要求とオーバーヘッドを追加し、2.25CPUと320MiBのメモリを持つNodeを探します。
PodがNodeにスケジュールされると、そのNodeのkubeletはPodのために新しいcgroupを生成します。基盤となるコンテナランタイムがコンテナを作成するのは、このPod内です。
リソースにコンテナごとの制限が定義されている場合(制限が定義されているGuaranteed QoSまたはBustrable QoS)、kubeletはそのリソース(CPUはcpu.cfs_quota_us、メモリはmemory.limit_in_bytes)に関連するPodのcgroupの上限を設定します。この上限は、コンテナの制限とPodSpecで定義されたオーバーヘッドの合計に基づきます。
CPUについては、PodがGuaranteedまたはBurstable QoSの場合、kubeletはコンテナの要求の合計とPodSpecに定義されたオーバーヘッドに基づいてcpu.shareを設定します。
次の例より、ワークロードに対するコンテナの要求を確認できます。
kubectl get pod test-pod -o jsonpath='{.spec.containers[*].resources.limits}'
コンテナの要求の合計は、CPUは2000m、メモリーは200MiBです。
map[cpu: 500m memory:100Mi] map[cpu:1500m memory:100Mi]
Nodeで観測される値と比較してみましょう。
kubectl describe node | grep test-pod -B2
出力では、2250mのCPUと320MiBのメモリーが要求されており、Podのオーバーヘッドが含まれていることが分かります。
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default test-pod 2250m (56%) 2250m (56%) 320Mi (1%) 320Mi (1%) 36m
Podのcgroupの制限を確認
ワークロードで実行中のNode上にある、Podのメモリーのcgroupを確認します。次に示す例では、CRI互換のコンテナランタイムのCLIを提供するNodeでcrictlを使用しています。これはPodのオーバーヘッドの動作を示すための高度な例であり、ユーザーがNode上で直接cgroupsを確認する必要はありません。
まず、特定のNodeで、Podの識別子を決定します。
# PodがスケジュールされているNodeで実行
POD_ID="$(sudo crictl pods --name test-pod -q)"
ここから、Podのcgroupのパスが決定します。
# PodがスケジュールされているNodeで実行
sudo crictl inspectp -o=json $POD_ID | grep cgroupsPath
結果のcgroupパスにはPodのポーズ中コンテナも含まれます。Podレベルのcgroupは1つ上のディレクトリです。
"cgroupsPath": "/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/7ccf55aee35dd16aca4189c952d83487297f3cd760f1bbf09620e206e7d0c27a"
今回のケースでは、Podのcgroupパスは、kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2となります。メモリーのPodレベルのcgroupの設定を確認しましょう。
# PodがスケジュールされているNodeで実行
# また、Podに割り当てられたcgroupと同じ名前に変更
cat /sys/fs/cgroup/memory/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/memory.limit_in_bytes
予想通り320MiBです。
335544320
Observability
Podのオーバヘッドが利用されているタイミングを特定し、定義されたオーバーヘッドで実行されているワークロードの安定性を観察するため、kube-state-metricsにはkube_pod_overheadというメトリクスが用意されています。この機能はv1.9のkube-state-metricsでは利用できませんが、次のリリースで期待されています。それまでは、kube-state-metricsをソースからビルドする必要があります。
次の項目
3 - TaintとToleration
Nodeアフィニティは Podの属性であり、あるNode群を引きつけます(優先条件または必須条件)。反対に taint はNodeがある種のPodを排除できるようにします。
toleration はPodに適用され、一致するtaintが付与されたNodeへPodがスケジューリングされることを認めるものです。ただしそのNodeへ必ずスケジューリングされるとは限りません。
taintとtolerationは組になって機能し、Podが不適切なNodeへスケジューリングされないことを保証します。taintはNodeに一つまたは複数個付与することができます。これはそのNodeがtaintを許容しないPodを受け入れるべきではないことを示します。
コンセプト
Nodeにtaintを付与するにはkubectl taintコマンドを使用します。 例えば、次のコマンドは
kubectl taint nodes node1 key1=value1:NoSchedule
node1にtaintを設定します。このtaintのキーはkey1、値はvalue1、taintの効果はNoScheduleです。
これはnode1にはPodに合致するtolerationがなければスケジューリングされないことを意味します。
上記のコマンドで付与したtaintを外すには、下記のコマンドを使います。
kubectl taint nodes node1 key1=value1:NoSchedule-
PodのtolerationはPodSpecの中に指定します。下記のtolerationはどちらも、上記のkubectl taintコマンドで追加したtaintと合致するため、どちらのtolerationが設定されたPodもnode1へスケジューリングされることができます。
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
tolerationを設定したPodの例を示します。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "example-key"
operator: "Exists"
effect: "NoSchedule"
operatorのデフォルトはEqualです。
tolerationがtaintと合致するのは、keyとeffectが同一であり、さらに下記の条件のいずれかを満たす場合です。
operatorがExists(valueを指定すべきでない場合)operatorがEqualであり、かつvalueが同一である場合
2つ特殊な場合があります。
空のkeyと演算子Existsは全てのkey、value、effectと一致するため、すべてのtaintと合致します。
空のeffectはkey1が一致する全てのeffectと合致します。
上記の例ではeffectにNoScheduleを指定しました。代わりに、effectにPreferNoScheduleを指定することができます。
これはNoScheduleの「ソフトな」バージョンであり、システムはtaintに対応するtolerationが設定されていないPodがNodeへ配置されることを避けようとしますが、必須の条件とはしません。3つ目のeffectの値としてNoExecuteがありますが、これについては後述します。
同一のNodeに複数のtaintを付与することや、同一のPodに複数のtolerationを設定することができます。 複数のtaintやtolerationが設定されている場合、Kubernetesはフィルタのように扱います。最初はNodeの全てのtaintがある状態から始め、Podが対応するtolerationを持っているtaintは無視され外されていきます。無視されずに残ったtaintが効果を及ぼします。 具体的には、
- effect
NoScheduleのtaintが無視されず残った場合、KubernetesはそのPodをNodeへスケジューリングしません。 - effect
NoScheduleのtaintは残らず、effectPreferNoScheduleのtaintは残った場合、KubernetesはそのNodeへのスケジューリングをしないように試みます。 - effect
NoExecuteのtaintが残った場合、既に稼働中のPodはそのNodeから排除され、まだ稼働していないPodはスケジューリングされないようになります。
例として、下記のようなtaintが付与されたNodeを考えます。
kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoSchedule
Podには2つのtolerationが設定されています。
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
この例では、3つ目のtaintと合致するtolerationがないため、PodはNodeへはスケジューリングされません。
しかし、これらのtaintが追加された時点で、そのNodeでPodが稼働していれば続けて稼働することが可能です。 これは、Podのtolerationと合致しないtaintは3つあるtaintのうちの3つ目のtaintのみであり、それがNoScheduleであるためです。
一般に、effect NoExecuteのtaintがNodeに追加されると、合致するtolerationが設定されていないPodは即時にNodeから排除され、合致するtolerationが設定されたPodが排除されることは決してありません。
しかし、effectNoExecuteに対するtolerationはtolerationSecondsフィールドを任意で指定することができ、これはtaintが追加された後にそのNodeにPodが残る時間を示します。例えば、
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
この例のPodが稼働中で、対応するtaintがNodeへ追加された場合、PodはそのNodeに3600秒残り、その後排除されます。仮にtaintがそれよりも前に外された場合、Podは排除されません。
ユースケースの例
taintとtolerationは、実行されるべきではないNodeからPodを遠ざけたり、排除したりするための柔軟な方法です。いくつかのユースケースを示します。
-
専有Node: あるNode群を特定のユーザーに専有させたい場合、そのNode群へtaintを追加し(
kubectl taint nodes nodename dedicated=groupName:NoSchedule) 対応するtolerationをPodへ追加します(これを実現する最も容易な方法はカスタム アドミッションコントローラーを書くことです)。 tolerationが設定されたPodはtaintの設定された(専有の)Nodeと、クラスターにあるその他のNodeの使用が認められます。もしPodが必ず専有Nodeのみを使うようにしたい場合は、taintと同様のラベルをそのNode群に設定し(例:dedicated=groupName)、アドミッションコントローラーはNodeアフィニティを使ってPodがdedicated=groupNameのラベルの付いたNodeへスケジューリングすることが必要であるということも設定する必要があります。 -
特殊なハードウェアを備えるNode: クラスターの中の少数のNodeが特殊なハードウェア(例えばGPU)を備える場合、そのハードウェアを必要としないPodがスケジューリングされないようにして、後でハードウェアを必要とするPodができたときの余裕を確保したいことがあります。 これは特殊なハードウェアを持つNodeにtaintを追加(例えば
kubectl taint nodes nodename special=true:NoScheduleまたはkubectl taint nodes nodename special=true:PreferNoSchedule)して、ハードウェアを使用するPodに対応するtolerationを追加することで可能です。 専有Nodeのユースケースと同様に、tolerationを容易に適用する方法はカスタム アドミッションコントローラーを使うことです。 例えば、特殊なハードウェアを表すために拡張リソース を使い、ハードウェアを備えるNodeに拡張リソースの名称のtaintを追加して、 拡張リソースtoleration アドミッションコントローラーを実行することが推奨されます。Nodeにはtaintが付与されているため、tolerationのないPodはスケジューリングされません。しかし拡張リソースを要求するPodを作成しようとすると、拡張リソースtolerationアドミッションコントローラーはPodに自動的に適切なtolerationを設定し、Podはハードウェアを備えるNodeへスケジューリングされます。 これは特殊なハードウェアを備えたNodeではそれを必要とするPodのみが稼働し、Podに対して手作業でtolerationを追加しなくて済むようにします。 -
taintを基にした排除: Nodeに問題が起きたときにPodごとに排除する設定を行うことができます。次のセクションにて説明します。
taintを基にした排除
Kubernetes v1.18 [stable]
上述したように、effect NoExecuteのtaintはNodeで実行中のPodに次のような影響を与えます。
- 対応するtolerationのないPodは即座に除外される
- 対応するtolerationがあり、それに
tolerationSecondsが指定されていないPodは残り続ける - 対応するtolerationがあり、それに
tolerationSecondsが指定されているPodは指定された間、残される
Nodeコントローラーは特定の条件を満たす場合に自動的にtaintを追加します。 組み込まれているtaintは下記の通りです。
node.kubernetes.io/not-ready: Nodeの準備ができていない場合。これはNodeConditionReadyがFalseである場合に対応します。node.kubernetes.io/unreachable: NodeがNodeコントローラーから到達できない場合。これはNodeConditionReadyがUnknownの場合に対応します。node.kubernetes.io/out-of-disk: Nodeのディスクの空きがない場合。node.kubernetes.io/memory-pressure: Nodeのメモリーが不足している場合。node.kubernetes.io/disk-pressure: Nodeのディスクが不足している場合。node.kubernetes.io/network-unavailable: Nodeのネットワークが利用できない場合。node.kubernetes.io/unschedulable: Nodeがスケジューリングできない場合。node.cloudprovider.kubernetes.io/uninitialized: kubeletが外部のクラウド事業者により起動されたときに設定されるtaintで、このNodeは利用不可能であることを示します。cloud-controller-managerによるコントローラーがこのNodeを初期化した後にkubeletはこのtaintを外します。
Nodeから追い出すときには、Nodeコントローラーまたはkubeletは関連するtaintをNoExecute効果の状態で追加します。
不具合のある状態から通常の状態へ復帰した場合は、kubeletまたはNodeコントローラーは関連するtaintを外すことができます。
PodにtolerationSecondsを指定することで不具合があるか応答のないNodeに残る時間を指定することができます。
例えば、ローカルの状態を多数持つアプリケーションとネットワークが分断された場合を考えます。ネットワークが復旧して、Podを排除しなくて済むことを見込んで、長時間Nodeから排除されないようにしたいこともあるでしょう。 この場合Podに設定するtolerationは次のようになります。
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000
Kubernetesはユーザーまたはコントローラーが明示的に指定しない限り、自動的にnode.kubernetes.io/not-readyとnode.kubernetes.io/unreachableに対するtolerationをtolerationSeconds=300にて設定します。
自動的に設定されるtolerationは、taintに対応する問題がNodeで検知されても5分間はそのNodeにPodが残されることを意味します。
DaemonSetのPodは次のtaintに対してNoExecuteのtolerationがtolerationSecondsを指定せずに設定されます。
node.kubernetes.io/unreachablenode.kubernetes.io/not-ready
これはDaemonSetのPodはこれらの問題によって排除されないことを保証します。
条件によるtaintの付与
NodeのライフサイクルコントローラーはNodeの状態に応じてNoSchedule効果のtaintを付与します。
スケジューラーはNodeの状態ではなく、taintを確認します。
Nodeに何がスケジューリングされるかは、そのNodeの状態に影響されないことを保証します。ユーザーは適切なtolerationをPodに付与することで、どの種類のNodeの問題を無視するかを選ぶことができます。
DaemonSetのコントローラーは、DaemonSetが中断されるのを防ぐために自動的に次のNoScheduletolerationを全てのDaemonSetに付与します。
node.kubernetes.io/memory-pressurenode.kubernetes.io/disk-pressurenode.kubernetes.io/out-of-disk(重要なPodのみ)node.kubernetes.io/unschedulable(1.10またはそれ以降)node.kubernetes.io/network-unavailable(ホストネットワークのみ)
これらのtolerationを追加することは後方互換性を保証します。DaemonSetに任意のtolerationを加えることもできます。
次の項目
4 - Kubernetesのスケジューラー
Kubernetesにおいて、スケジューリング とは、KubeletがPodを稼働させるためにNodeに割り当てることを意味します。
スケジューリングの概要
スケジューラーは新規に作成されたPodで、Nodeに割り当てられていないものを監視します。スケジューラーは発見した各Podのために、稼働させるべき最適なNodeを見つけ出す責務を担っています。そのスケジューラーは下記で説明するスケジューリングの原理を考慮に入れて、NodeへのPodの割り当てを行います。
Podが特定のNodeに割り当てられる理由を理解したい場合や、カスタムスケジューラーを自身で作ろうと考えている場合、このページはスケジューリングに関して学ぶのに役立ちます。
kube-scheduler
kube-schedulerはKubernetesにおけるデフォルトのスケジューラーで、コントロールプレーンの一部分として稼働します。 kube-schedulerは、もし希望するのであれば自分自身でスケジューリングのコンポーネントを実装でき、それを代わりに使用できるように設計されています。
kube-schedulerは、新規に作成された各Podや他のスケジューリングされていないPodを稼働させるために最適なNodeを選択します。 しかし、Pod内の各コンテナにはそれぞれ異なるリソースの要件があり、各Pod自体にもそれぞれ異なる要件があります。そのため、既存のNodeは特定のスケジューリング要求によってフィルターされる必要があります。
クラスター内でPodに対する割り当て要求を満たしたNodeは 割り当て可能 なNodeと呼ばれます。 もし適切なNodeが一つもない場合、スケジューラーがNodeを割り当てることができるまで、そのPodはスケジュールされずに残ります。
スケジューラーはPodに対する割り当て可能なNodeをみつけ、それらの割り当て可能なNodeにスコアをつけます。その中から最も高いスコアのNodeを選択し、Podに割り当てるためのいくつかの関数を実行します。 スケジューラーは binding と呼ばれる処理中において、APIサーバーに対して割り当てが決まったNodeの情報を通知します。
スケジューリングを決定する上で考慮が必要な要素としては、個別または複数のリソース要求や、ハードウェア/ソフトウェアのポリシー制約、affinityやanti-affinityの設定、データの局所性や、ワークロード間での干渉などが挙げられます。
kube-schedulerによるスケジューリング
kube-schedulerは2ステップの操作によってPodに割り当てるNodeを選択します。
-
フィルタリング
-
スコアリング
フィルタリング ステップでは、Podに割り当て可能なNodeのセットを探します。例えばPodFitsResourcesフィルターは、Podのリソース要求を満たすのに十分なリソースをもつNodeがどれかをチェックします。このステップの後、候補のNodeのリストは、要求を満たすNodeを含みます。 たいてい、リストの要素は複数となります。もしこのリストが空の場合、そのPodはスケジュール可能な状態とはなりません。
スコアリング ステップでは、Podを割り当てるのに最も適したNodeを選択するために、スケジューラーはリストの中のNodeをランク付けします。 スケジューラーは、フィルタリングによって選ばれた各Nodeに対してスコアを付けます。このスコアはアクティブなスコア付けのルールに基づいています。
最後に、kube-schedulerは最も高いランクのNodeに対してPodを割り当てます。もし同一のスコアのNodeが複数ある場合は、kube-schedulerがランダムに1つ選択します。
スケジューラーのフィルタリングとスコアリングの動作に関する設定には2つのサポートされた手法があります。
- スケジューリングポリシー は、フィルタリングのための Predicates とスコアリングのための Priorities の設定することができます。
- スケジューリングプロファイルは、
QueueSort、Filter、Score、Bind、Reserve、Permitやその他を含む異なるスケジューリングの段階を実装するプラグインを設定することができます。kube-schedulerを異なるプロファイルを実行するように設定することもできます。
次の項目
- スケジューラーのパフォーマンスチューニングを参照してください。
- Podトポロジーの分散制約を参照してください。
- kube-schedulerのリファレンスドキュメントを参照してください。
- 複数のスケジューラーの設定について学んでください。
- トポロジーの管理ポリシーについて学んでください。
- Podのオーバーヘッドについて学んでください。
- ボリュームを使用するPodのスケジューリングについて以下で学んでください。
5 - スケジューラーのパフォーマンスチューニング
Kubernetes 1.14 [beta]
kube-schedulerはKubernetesのデフォルトのスケジューラーです。クラスター内のノード上にPodを割り当てる責務があります。
クラスター内に存在するノードで、Podのスケジューリング要求を満たすものはPodに対して割り当て可能なノードと呼ばれます。スケジューラーはPodに対する割り当て可能なノードをみつけ、それらの割り当て可能なノードにスコアをつけます。その中から最も高いスコアのノードを選択し、Podに割り当てるためのいくつかの関数を実行します。スケジューラーはBindingと呼ばれる処理中において、APIサーバーに対して割り当てが決まったノードの情報を通知します。
このページでは、大規模のKubernetesクラスターにおけるパフォーマンス最適化のためのチューニングについて説明します。
大規模クラスターでは、レイテンシー(新規Podをすばやく配置)と精度(スケジューラーが不適切な配置を行うことはめったにありません)の間でスケジューリング結果を調整するスケジューラーの動作をチューニングできます。
このチューニング設定は、kube-scheduler設定のpercentageOfNodesToScoreで設定できます。KubeSchedulerConfiguration設定は、クラスター内のノードにスケジュールするための閾値を決定します。
閾値の設定
percentageOfNodesToScoreオプションは、0から100までの数値を受け入れます。0は、kube-schedulerがコンパイル済みのデフォルトを使用することを示す特別な値です。
percentageOfNodesToScoreに100より大きな値を設定した場合、kube-schedulerの挙動は100を設定した場合と同様となります。
この値を変更するためには、kube-schedulerの設定ファイル(これは/etc/kubernetes/config/kube-scheduler.yamlの可能性が高い)を編集し、スケジューラーを再起動します。
この変更をした後、
kubectl get pods -n kube-system | grep kube-scheduler
を実行して、kube-schedulerコンポーネントが正常であることを確認できます。
ノードへのスコア付けの閾値
スケジューリング性能を改善するため、kube-schedulerは割り当て可能なノードが十分に見つかるとノードの検索を停止できます。大規模クラスターでは、すべてのノードを考慮する単純なアプローチと比較して時間を節約できます。
クラスター内のすべてのノードに対する十分なノード数を整数パーセンテージで指定します。kube-schedulerは、これをノード数に変換します。スケジューリング中に、kube-schedulerが設定されたパーセンテージを超える十分な割り当て可能なノードを見つけた場合、kube-schedulerはこれ以上割り当て可能なノードを探すのを止め、スコアリングフェーズに進みます。
スケジューラーはどのようにノードを探索するかで処理を詳しく説明しています。
デフォルトの閾値
閾値を指定しない場合、Kubernetesは100ノードのクラスタでは50%、5000ノードのクラスタでは10%になる線形方程式を使用して数値を計算します。自動計算の下限は5%です。
つまり、明示的にpercentageOfNodesToScoreを5未満の値を設定しない限り、クラスターの規模に関係なく、kube-schedulerは常に少なくともクラスターの5%のノードに対してスコア付けをします。
スケジューラーにクラスター内のすべてのノードに対してスコア付けをさせる場合は、percentageOfNodesToScoreの値に100を設定します。
例
percentageOfNodesToScoreの値を50%に設定する例は下記のとおりです。
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
algorithmSource:
provider: DefaultProvider
...
percentageOfNodesToScore: 50
percentageOfNodesToScoreのチューニング
percentageOfNodesToScoreは1から100の間の範囲である必要があり、デフォルト値はクラスターのサイズに基づいて計算されます。また、クラスターのサイズの最小値は50ノードとハードコードされています。
割り当て可能なノードが50以下のクラスタでは、スケジューラの検索を早期に停止するのに十分な割り当て可能なノードがないため、スケジューラはすべてのノードをチェックします。
小規模クラスタでは、percentageOfNodesToScoreに低い値を設定したとしても、同様の理由で変更による影響は全くないか、ほとんどありません。
クラスターのノード数が数百以下の場合は、この設定オプションをデフォルト値のままにします。変更してもスケジューラの性能を大幅に改善する可能性はほとんどありません。
この値を設定する際に考慮するべき重要な注意事項として、割り当て可能ノードのチェック対象のノードが少ないと、一部のノードはPodの割り当てのためにスコアリングされなくなります。結果として、高いスコアをつけられる可能性のあるノードがスコアリングフェーズに渡されることがありません。これにより、Podの配置が理想的なものでなくなります。
kube-schedulerが頻繁に不適切なPodの配置を行わないよう、percentageOfNodesToScoreをかなり低い値を設定することは避けるべきです。スケジューラのスループットがアプリケーションにとって致命的で、ノードのスコアリングが重要でない場合を除いて、10%未満に設定することは避けてください。言いかえると、割り当て可能な限り、Podは任意のノード上で稼働させるのが好ましいです。
スケジューラーはどのようにノードを探索するか
このセクションでは、この機能の内部の詳細を理解したい人向けになります。
クラスター内の全てのノードに対して平等にPodの割り当ての可能性を持たせるため、スケジューラーはラウンドロビン方式でノードを探索します。複数のノードの配列になっているイメージです。スケジューラーはその配列の先頭から探索を開始し、percentageOfNodesToScoreによって指定された数のノードを検出するまで、割り当て可能かどうかをチェックしていきます。次のPodでは、スケジューラーは前のPodの割り当て処理でチェックしたところから探索を再開します。
ノードが複数のゾーンに存在するとき、スケジューラーは様々なゾーンのノードを探索して、異なるゾーンのノードが割り当て可能かどうかのチェック対象になるようにします。例えば2つのゾーンに6つのノードがある場合を考えます。
Zone 1: Node 1, Node 2, Node 3, Node 4
Zone 2: Node 5, Node 6
スケジューラーは、下記の順番でノードの割り当て可能性を評価します。
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
全てのノードのチェックを終えたら、1番目のノードに戻ってチェックをします。
6 - スケジューリングフレームワーク
Kubernetes v1.19 [stable]
スケジューリングフレームワークはKubernetesのスケジューラーに対してプラグイン可能なアーキテクチャです。 このアーキテクチャは、既存のスケジューラーに新たに「プラグイン」としてAPI群を追加するもので、プラグインはスケジューラー内部にコンパイルされます。このAPI群により、スケジューリングの「コア」の軽量かつ保守しやすい状態に保ちながら、ほとんどのスケジューリングの機能をプラグインとして実装することができます。このフレームワークの設計に関する技術的な情報についてはこちらのスケジューリングフレームワークの設計提案をご覧ください。
フレームワークのワークフロー
スケジューリングフレームワークは、いくつかの拡張点を定義しています。スケジューラープラグインは、1つ以上の拡張点で呼び出されるように登録します。これらのプラグインの中には、スケジューリングの決定を変更できるものから、単に情報提供のみを行うだけのものなどがあります。
この1つのPodをスケジュールしようとする各動作はScheduling CycleとBinding Cycleの2つのフェーズに分けられます。
Scheduling Cycle & Binding Cycle
Scheduling CycleではPodが稼働するNodeを決定し、Binding Cycleではそれをクラスターに適用します。この2つのサイクルを合わせて「スケジューリングコンテキスト」と呼びます。
Scheduling CycleではPodに対して1つ1つが順番に実行され、Binding Cyclesでは並列に実行されます。
Podがスケジューリング不能と判断された場合や、内部エラーが発生した場合、Scheduling CycleまたはBinding Cycleを中断することができます。その際、Podはキューに戻され再試行されます。
拡張点
次の図はPodに対するスケジューリングコンテキストとスケジューリングフレームワークが公開する拡張点を示しています。この図では「Filter」がフィルタリングのための「Predicate」、「Scoring」がスコアリングのための「Priorities」機能に相当します。
1つのプラグインを複数の拡張点に登録することで、より複雑なタスクやステートフルなタスクを実行することができます。
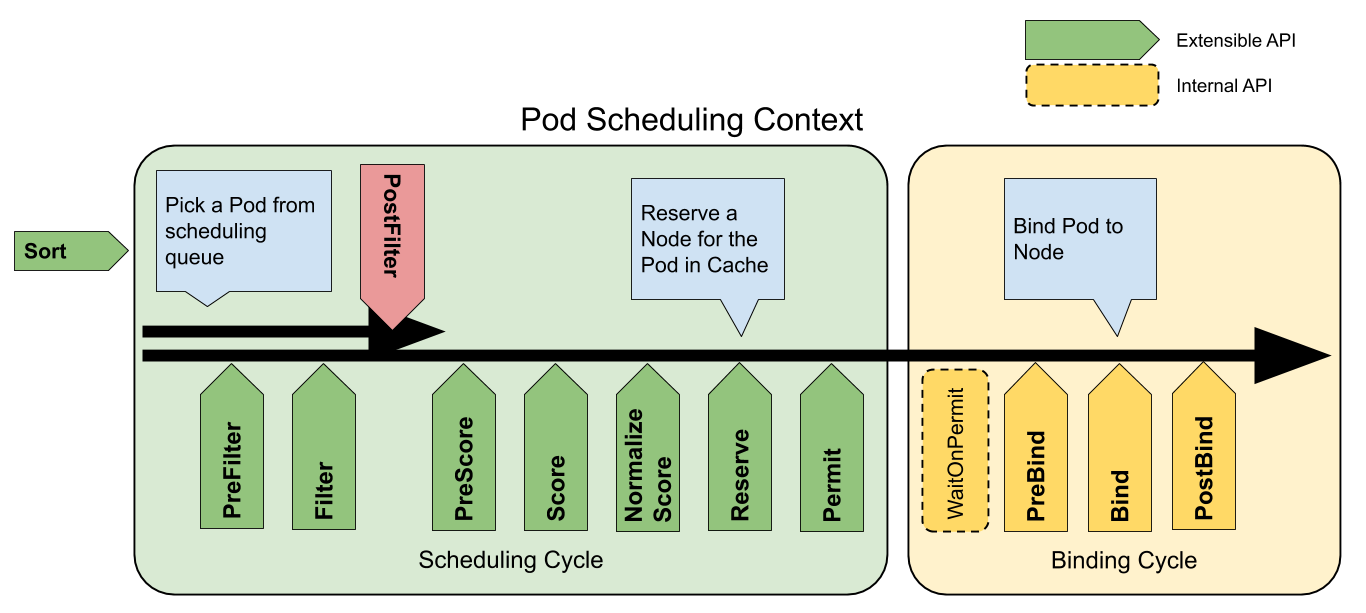
scheduling framework extension points
QueueSort
これらのプラグインはスケジューリングキュー内のPodをソートするために使用されます。このプラグインは、基本的にLess(Pod1, Pod2)という関数を提供します。また、このプラグインは、1つだけ有効化できます。
PreFilter
これらのプラグインは、Podに関する情報を前処理したり、クラスターやPodが満たすべき特定の条件をチェックするために使用されます。もし、PreFilterプラグインのいずれかがエラーを返した場合、Scheduling Cycleは中断されます。
Filter
FilterプラグインはPodを実行できないNodeを候補から除外します。各Nodeに対して、スケジューラーは設定された順番でFilterプラグインを呼び出します。もし、いずれかのFilterプラグインが途中でそのNodeを実行不可能とした場合、残りのプラグインではそのNodeは呼び出されません。Nodeは同時に評価されることがあります。
PostFilter
これらのプラグインはFilterフェーズで、Podに対して実行可能なNodeが見つからなかった場合にのみ呼び出されます。このプラグインは設定された順番で呼び出されます。もしいずれかのPostFilterプラグインが、あるNodeを「スケジュール可能(Schedulable)」と目星をつけた場合、残りのプラグインは呼び出されません。典型的なPostFilterの実装はプリエンプション方式で、他のPodを先取りして、Podをスケジューリングできるようにしようとします。
PreScore
これらのプラグインは、Scoreプラグインが使用する共有可能な状態を生成する「スコアリングの事前」作業を行うために使用されます。このプラグインがエラーを返した場合、Scheduling Cycleは中断されます。
Score
これらのプラグインはフィルタリングのフェーズを通過したNodeをランク付けするために使用されます。スケジューラーはそれぞれのNodeに対して、それぞれのscoringプラグインを呼び出します。スコアの最小値と最大値の範囲が明確に定義されます。NormalizeScoreフェーズの後、スケジューラーは設定されたプラグインの重みに従って、全てのプラグインからNodeのスコアを足し合わせます。
NormalizeScore
これらのプラグインはスケジューラーが最終的なNodeの順位を計算する前にスコアを修正するために使用されます。この拡張点に登録されたプラグインは、同じプラグインのScoreの結果を使用して呼び出されます。各プラグインはScheduling Cycle毎に、1回呼び出されます。
例えば、BlinkingLightScorerというプラグインが、点滅する光の数に基づいてランク付けをするとします。
func ScoreNode(_ *v1.pod, n *v1.Node) (int, error) {
return getBlinkingLightCount(n)
}
ただし、NodeScoreMaxに比べ、点滅をカウントした最大値の方が小さい場合があります。これを解決するために、BlinkingLightScorerも拡張点に登録する必要があります。
func NormalizeScores(scores map[string]int) {
highest := 0
for _, score := range scores {
highest = max(highest, score)
}
for node, score := range scores {
scores[node] = score*NodeScoreMax/highest
}
}
NormalizeScoreプラグインが途中でエラーを返した場合、Scheduling Cycleは中断されます。
Reserve
Reserve拡張を実装したプラグインには、ReserveとUnreserve という2つのメソッドがあり、それぞれReserve
とUnreserveと呼ばれる2つの情報スケジューリングフェーズを返します。
実行状態を保持するプラグイン(別名「ステートフルプラグイン」)は、これらのフェーズを使用して、Podに対してNodeのリソースが予約されたり予約解除された場合に、スケジューラーから通知を受け取ります。
Reserveフェーズは、スケジューラーが実際にPodを指定されたNodeにバインドする前に発生します。このフェーズはスケジューラーがバインドが成功するのを待つ間にレースコンディションの発生を防ぐためにあります。
各ReserveプラグインのReserveメソッドは成功することも失敗することもあります。もしどこかのReserveメソッドの呼び出しが失敗すると、後続のプラグインは実行されず、Reserveフェーズは失敗したものとみなされます。全てのプラグインのReserveメソッドが成功した場合、Reserveフェーズは成功とみなされ、残りのScheduling CycleとBinding Cycleが実行されます。
Unreserveフェーズは、Reserveフェーズまたは後続のフェーズが失敗した場合に、呼び出されます。この時、全てのReserveプラグインのUnreserveメソッドが、Reserveメソッドの呼び出された逆の順序で実行されます。このフェーズは予約されたPodに関連する状態をクリーンアップするためにあります。
Unreserveメソッドの実装は冪等性を持つべきであり、この処理で問題があった場合に失敗させてはなりません。
Permit
Permit プラグインは、各PodのScheduling Cycleの終了時に呼び出され、候補Nodeへのバインドを阻止もしくは遅延させるために使用されます。permitプラグインは次の3つのうちどれかを実行できます。
-
承認(approve)
全てのPermitプラグインから承認(approve)されたPodは、バインド処理へ送られます。 -
拒否(deny)
もしどれか1つのPermitプラグインがPodを拒否(deny)した場合、そのPodはスケジューリングキューに戻されます。 これはReserveプラグイン内のUnreserveフェーズで呼び出されます。 -
待機(wait) (タイムアウトあり)
もしPermitプラグインが「待機(wait)」を返した場合、そのPodは内部の「待機中」Podリストに保持され、このPodに対するBinding Cycleは開始されるものの、承認(approve)されるまで直接ブロックされます。もしタイムアウトが発生した場合、この待機(wait)はdenyへ変わり、対象のPodはスケジューリングキューに戻されると共に、ReserveプラグインのUnreserveフェーズが呼び出されます。
FrameworkHandle)、その中の予約済みPodのバインドを承認(approve)できるのはPermitプラグインだけであると予想します。承認(approve)されたPodは、PreBindフェーズへ送られます。
PreBind
これらのプラグインは、Podがバインドされる前に必要な作業を行うために使用されます。例えば、Podの実行を許可する前に、ネットワークボリュームをプロビジョニングし、Podを実行予定のNodeにマウントすることができます。
もし、いずれかのPreBindプラグインがエラーを返した場合、Podは拒否され、スケジューリングキューに戻されます。
Bind
これらのプラグインはPodをNodeにバインドするために使用されます。このプラグインは全てのPreBindプラグインの処理が完了するまで呼ばれません。それぞれのBindプラグインは設定された順序で呼び出されます。このプラグインは、与えられたPodを処理するかどうかを選択することができます。もしPodを処理することを選択した場合、残りのBindプラグインは全てスキップされます。
PostBind
これは単に情報提供のための拡張点です。Post-bindプラグインはPodのバインドが成功した後に呼び出されます。これはBinding Cycleの最後であり、関連するリソースのクリーンアップに使用されます。
プラグインAPI
プラグインAPIには2つの段階があります。まず、プラグインを登録し設定することです。そして、拡張点インターフェースを使用することです。このインターフェースは次のような形式をとります。
type Plugin interface {
Name() string
}
type QueueSortPlugin interface {
Plugin
Less(*v1.pod, *v1.pod) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter(context.Context, *framework.CycleState, *v1.pod) error
}
// ...
プラグインの設定
スケジューラーの設定でプラグインを有効化・無効化することができます。Kubernetes v1.18以降を使用しているなら、ほとんどのスケジューリングプラグインは使用されており、デフォルトで有効になっています。
デフォルトのプラグインに加えて、独自のスケジューリングプラグインを実装し、デフォルトのプラグインと一緒に使用することも可能です。詳しくはスケジューラープラグインをご覧下さい。
Kubernetes v1.18以降を使用しているなら、プラグインのセットをスケジューラープロファイルとして設定し、様々な種類のワークロードに適合するように複数のプロファイルを定義することが可能です。詳しくは複数のプロファイルをご覧下さい。