Kubernetesを拡張する
Kubernetesクラスターの挙動を変えるいろいろな方法
Kubernetesは柔軟な設定が可能で、高い拡張性を持っています。
結果として、Kubernetesのプロジェクトソースコードをフォークしたり、パッチを当てて利用することは滅多にありません。
このガイドは、Kubernetesクラスターをカスタマイズするための選択肢を記載します。
管理しているKubernetesクラスターを、動作環境の要件にどのように適合させるべきかを理解したいクラスター管理者を対象にしています。
将来の プラットフォーム開発者 、またはKubernetesプロジェクトのコントリビューターにとっても、どのような拡張のポイントやパターンが存在するのか、また、それぞれのトレードオフや制限事項を学ぶための導入として役立つでしょう。
概要
カスタマイズのアプローチには大きく分けて、フラグ、ローカル設定ファイル、またはAPIリソースの変更のみを含んだ 設定 と、稼働しているプログラムまたはサービスも含んだ 拡張 があります。このドキュメントでは、主に拡張について説明します。
設定
設定ファイル と フラグ はオンラインドキュメントのリファレンスセクションの中の、各項目に記載されています:
ホスティングされたKubernetesサービスやマネージドなKubernetesでは、フラグと設定ファイルが常に変更できるとは限りません。変更可能な場合でも、通常はクラスターの管理者のみが変更できます。また、それらは将来のKubernetesバージョンで変更される可能性があり、設定変更にはプロセスの再起動が必要になるかもしれません。これらの理由により、この方法は他の選択肢が無いときにのみ利用するべきです。
ResourceQuota、PodSecurityPolicy、NetworkPolicy、そしてロールベースアクセス制御(RBAC)といった ビルトインポリシーAPI は、ビルトインのKubernetes APIです。APIは通常、ホスティングされたKubernetesサービスやマネージドなKubernetesで利用されます。これらは宣言的で、Podのような他のKubernetesリソースと同じ慣例に従っています。そのため、新しいクラスターの設定は繰り返し再利用することができ、アプリケーションと同じように管理することが可能です。さらに、安定版(stable)を利用している場合、他のKubernetes APIのような定義済みのサポートポリシーを利用することができます。これらの理由により、この方法は、適切な用途の場合、 設定ファイル や フラグ よりも好まれます。
拡張
拡張はKubernetesを拡張し、深く統合されたソフトウェアの構成要素です。
これは新しいタイプと、新しい種類のハードウェアをサポートするために利用されます。
ほとんどのクラスター管理者は、ホスティングされている、またはディストリビューションとしてのKubernetesを使っているでしょう。
結果として、ほとんどのKubernetesユーザーは既存の拡張を使えばよいため、新しい拡張を書く必要は無いと言えます。
拡張パターン
Kubernetesは、クライアントのプログラムを書くことで自動化ができるようにデザインされています。
Kubernetes APIに読み書きをするどのようなプログラムも、役に立つ自動化機能を提供することができます。
自動化機能 はクラスター上、またはクラスター外で実行できます。
このドキュメントに後述のガイダンスに従うことで、高い可用性を持つ頑強な自動化機能を書くことができます。
自動化機能は通常、ホスティングされているクラスター、マネージドな環境など、どのKubernetesクラスター上でも動きます。
Kubernetes上でうまく動くクライアントプログラムを書くために、コントローラー パターンという明確なパターンがあります。
コントローラーは通常、オブジェクトの .spec を読み取り、何らかの処理をして、オブジェクトの .status を更新します。
コントローラーはKubernetesのクライアントです。Kubernetesがクライアントとして動き、外部のサービスを呼び出す場合、それは Webhook と呼ばれます。
呼び出されるサービスは Webhookバックエンド と呼ばれます。コントローラーのように、Webhookも障害点を追加します。
Webhookのモデルでは、Kubernetesは外部のサービスを呼び出します。
バイナリプラグイン モデルでは、Kubernetesはバイナリ(プログラム)を実行します。
バイナリプラグインはkubelet(例、FlexVolumeプラグイン、ネットワークプラグイン)、またkubectlで利用されています。
下図は、それぞれの拡張ポイントが、Kubernetesのコントロールプレーンとどのように関わっているかを示しています。
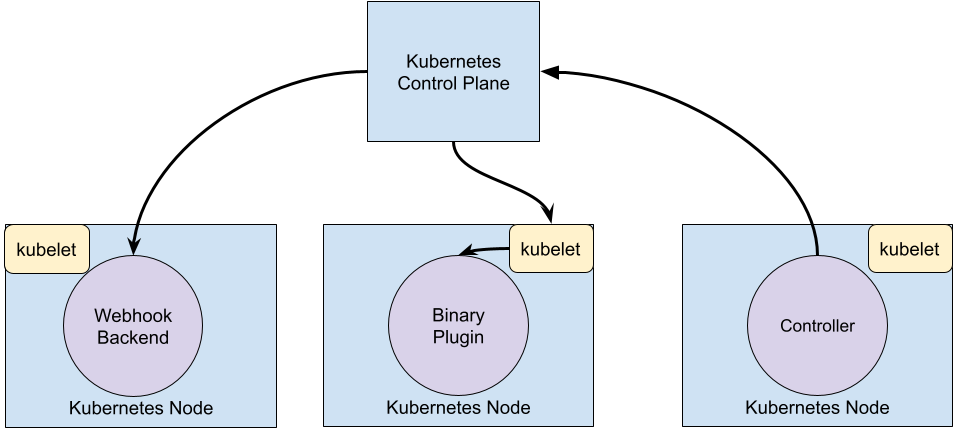
拡張ポイント
この図は、Kubernetesにおける拡張ポイントを示しています。
- ユーザーは頻繁に
kubectlを使って、Kubernetes APIとやり取りをします。Kubectlプラグインは、kubectlのバイナリを拡張します。これは個別ユーザーのローカル環境のみに影響を及ぼすため、サイト全体にポリシーを強制することはできません。
- APIサーバーは全てのリクエストを処理します。APIサーバーのいくつかの拡張ポイントは、リクエストを認可する、コンテキストに基づいてブロックする、リクエストを編集する、そして削除を処理することを可能にします。これらはAPIアクセス拡張セクションに記載されています。
- APIサーバーは様々な種類の リソース を扱います。
Podのような ビルトインリソース はKubernetesプロジェクトにより定義され、変更できません。ユーザーも、自身もしくは、他のプロジェクトで定義されたリソースを追加することができます。それは カスタムリソース と呼ばれ、カスタムリソースセクションに記載されています。カスタムリソースは度々、APIアクセス拡張と一緒に使われます。
- KubernetesのスケジューラーはPodをどのノードに配置するかを決定します。スケジューリングを拡張するには、いくつかの方法があります。それらはスケジューラー拡張セクションに記載されています。
- Kubernetesにおける多くの振る舞いは、APIサーバーのクライアントであるコントローラーと呼ばれるプログラムに実装されています。コントローラーは度々、カスタムリソースと共に使われます。
- kubeletはサーバー上で実行され、Podが仮想サーバーのようにクラスターネットワーク上にIPを持った状態で起動することをサポートします。ネットワークプラグインがPodのネットワーキングにおける異なる実装を適用することを可能にします。
- kubeletはまた、コンテナのためにボリュームをマウント、アンマウントします。新しい種類のストレージはストレージプラグインを通じてサポートされます。
もしあなたがどこから始めるべきかわからない場合、このフローチャートが役立つでしょう。一部のソリューションは、いくつかの種類の拡張を含んでいることを留意してください。
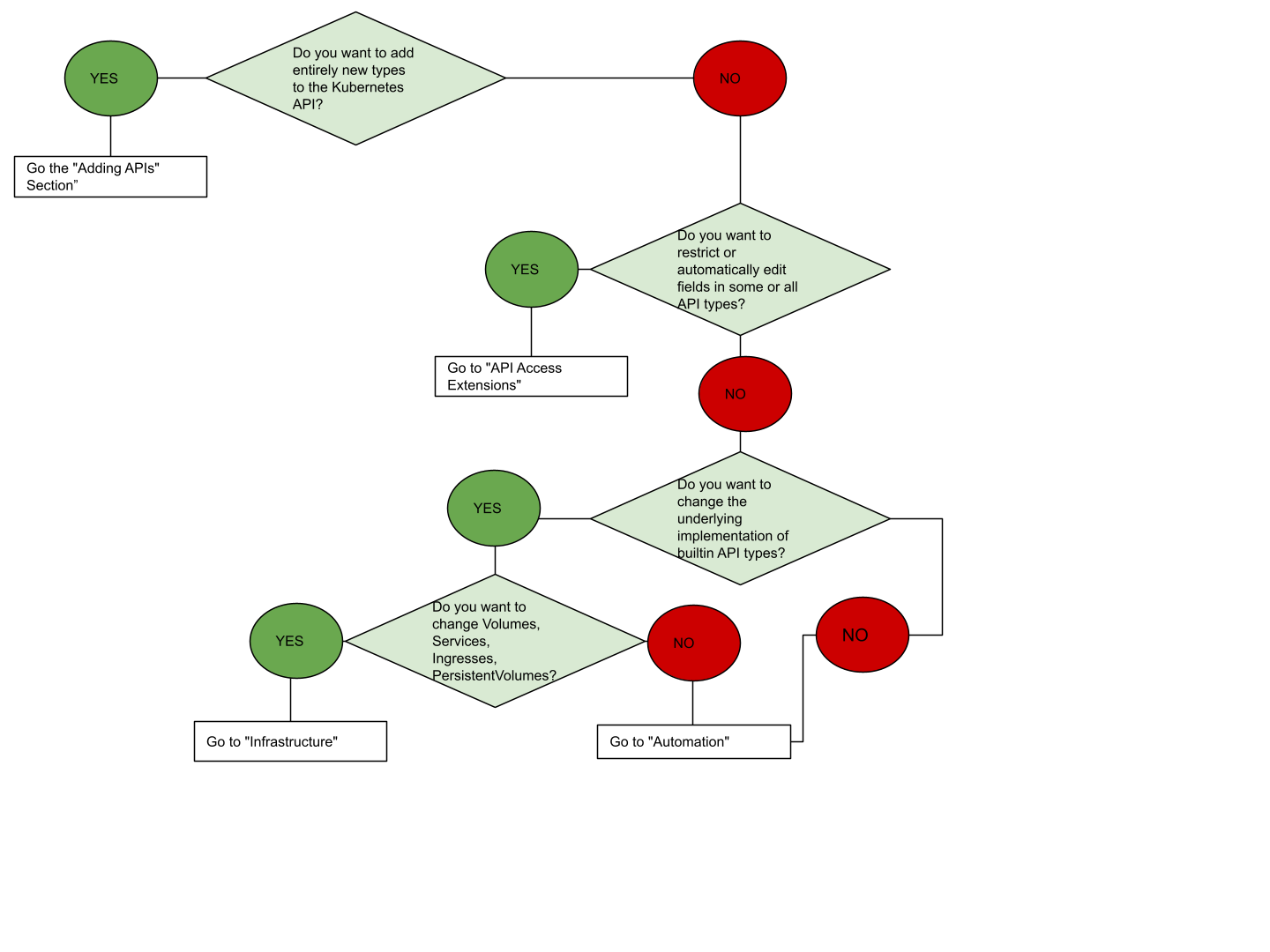
API拡張
ユーザー定義タイプ
新しいコントローラー、アプリケーションの設定に関するオブジェクト、また宣言型APIを定義し、それらをkubectlのようなKubernetesのツールから管理したい場合、Kubernetesにカスタムリソースを追加することを検討して下さい。
カスタムリソースはアプリケーション、ユーザー、監視データのデータストレージとしては使わないで下さい。
カスタムリソースに関するさらなる情報は、カスタムリソースコンセプトガイドを参照して下さい。
新しいAPIと自動化機能の連携
カスタムリソースAPIと制御ループの組み合わせはオペレーターパターンと呼ばれています。オペレーターパターンは、通常ステートフルな特定のアプリケーションを管理するために利用されます。これらのカスタムAPIと制御ループは、ストレージ、またはポリシーのような他のリソースを管理するためにも利用されます。
ビルトインリソースの変更
カスタムリソースを追加し、KubernetesAPIを拡張する場合、新たに追加されたリソースは常に新しいAPIグループに分類されます。既存のAPIグループを置き換えたり、変更することはできません。APIを追加することは直接、既存のAPI(例、Pod)の振る舞いに影響を与えることは無いですが、APIアクセス拡張の場合、その可能性があります。
APIアクセス拡張
リクエストがKubernetes APIサーバーに到達すると、まず最初に認証が行われ、次に認可、その後、様々なAdmission Controlの対象になります。このフローの詳細はKubernetes APIへのアクセスをコントロールするを参照して下さい。
これらの各ステップごとに拡張ポイントが用意されています。
Kubdernetesはいくつかのビルトイン認証方式をサポートしています。それは認証プロキシの後ろに配置することも可能で、認可ヘッダーを通じて(Webhookの)検証のために外部サービスにトークンを送ることもできます。全てのこれらの方法は認証ドキュメントでカバーされています。
認証
認証は、全てのリクエストのヘッダーまたは証明書情報を、リクエストを投げたクライアントのユーザー名にマッピングします。
Kubernetesはいくつかのビルトイン認証方式と、それらが要件に合わない場合、認証Webhookを提供します。
認可
認可は特定のユーザーがAPIリソースに対して、読み込み、書き込み、そしてその他の操作が可能かどうかを決定します。それはオブジェクト全体のレベルで機能し、任意のオブジェクトフィールドに基づいての区別は行いません。もしビルトインの認可メカニズムが要件に合わない場合、認可Webhookが、ユーザー提供のコードを呼び出し認可の決定を行うことを可能にします。
動的Admission Control
リクエストが認可された後、もしそれが書き込み操作だった場合、リクエストはAdmission Controlのステップを通ります。ビルトインのステップに加え、いくつかの拡張が存在します:
インフラストラクチャ拡張
ストレージプラグイン
Flex Volumesは、Kubeletがバイナリプラグインを呼び出してボリュームをマウントすることにより、ユーザーはビルトインのサポートなしでボリュームタイプをマウントすることを可能にします。
デバイスプラグイン
デバイスプラグインを通じて、ノードが新たなノードのリソース(CPU、メモリなどのビルトインのものに加え)を見つけることを可能にします。
ネットワークプラグイン
他のネットワークファブリックがネットワークプラグインを通じてサポートされます。
スケジューラー拡張
スケジューラーは特別な種類のコントローラーで、Podを監視し、Podをノードに割り当てます。デフォルトのコントローラーを完全に置き換えることもできますが、他のKubernetesのコンポーネントの利用を継続する、または複数のスケジューラーを同時に動かすこともできます。
これはかなりの大きな作業で、ほとんど全てのKubernetesユーザーはスケジューラーを変更する必要はありません。
スケジューラはWebhookもサポートしており、Webhookバックエンド(スケジューラー拡張)を通じてPodを配置するために選択されたノードをフィルタリング、優先度付けすることが可能です。
次の項目
1 - Kubernetesクラスターの拡張
Kubernetesは柔軟な設定が可能で、高い拡張性を持っています。
結果として、Kubernetesのプロジェクトソースコードをフォークしたり、パッチを当てて利用することは滅多にありません。
このガイドは、Kubernetesクラスターをカスタマイズするための選択肢を記載します。
管理しているKubernetesクラスターを、動作環境の要件にどのように適合させるべきかを理解したいクラスター管理者を対象にしています。
将来の プラットフォーム開発者 、またはKubernetesプロジェクトのコントリビューターにとっても、どのような拡張のポイントやパターンが存在するのか、また、それぞれのトレードオフや制限事項を学ぶための導入として役立つでしょう。
概要
カスタマイズのアプローチには大きく分けて、フラグ、ローカル設定ファイル、またはAPIリソースの変更のみを含んだ コンフィグレーション と、稼働しているプログラムまたはサービスも含んだ エクステンション があります。このドキュメントでは、主にエクステンションについて説明します。
コンフィグレーション
設定ファイル と フラグ はオンラインドキュメントのリファレンスセクションの中の、各項目に記載されています:
ホスティングされたKubernetesサービスやマネージドなKubernetesでは、フラグと設定ファイルが常に変更できるとは限りません。変更可能な場合でも、通常はクラスターの管理者のみが変更できます。また、それらは将来のKubernetesバージョンで変更される可能性があり、設定変更にはプロセスの再起動が必要になるかもしれません。これらの理由により、この方法は他の選択肢が無いときにのみ利用するべきです。
ResourceQuota、PodSecurityPolicy、NetworkPolicy、そしてロールベースアクセス制御(RBAC)といった ビルトインポリシーAPI は、ビルトインのKubernetes APIです。APIは通常、ホスティングされたKubernetesサービスやマネージドなKubernetesで利用されます。これらは宣言的で、Podのような他のKubernetesリソースと同じ慣例に従っています。そのため、新しいクラスターの設定は繰り返し再利用することができ、アプリケーションと同じように管理することが可能です。さらに、安定版(stable)を利用している場合、他のKubernetes APIのような定義済みのサポートポリシーを利用することができます。これらの理由により、この方法は、適切な用途の場合、 設定ファイル や フラグ よりも好まれます。
エクステンション
エクステンションはKubernetesを拡張し、深く統合されたソフトウェアの構成要素です。
これは新しいタイプと、新しい種類のハードウェアをサポートするために利用されます。
ほとんどのクラスター管理者は、ホスティングされている、またはディストリビューションとしてのKubernetesを使っているでしょう。
結果として、ほとんどのKubernetesユーザーは既存のエクステンションを使えばよいため、新しいエクステンションを書く必要は無いと言えます。
エクステンションパターン
Kubernetesは、クライアントのプログラムを書くことで自動化ができるようにデザインされています。
Kubernetes APIに読み書きをするどのようなプログラムも、役に立つ自動化機能を提供することができます。
自動化機能 はクラスター上、またはクラスター外で実行できます。
このドキュメントに後述のガイダンスに従うことで、高い可用性を持つ頑強な自動化機能を書くことができます。
自動化機能は通常、ホスティングされているクラスター、マネージドな環境など、どのKubernetesクラスター上でも動きます。
Kubernetes上でうまく動くクライアントプログラムを書くために、コントローラー パターンという明確なパターンがあります。
コントローラーは通常、オブジェクトの .spec を読み取り、何らかの処理をして、オブジェクトの .status を更新します。
コントローラーはKubernetesのクライアントです。Kubernetesがクライアントとして動き、外部のサービスを呼び出す場合、それは Webhook と呼ばれます。
呼び出されるサービスは Webhookバックエンド と呼ばれます。コントローラーのように、Webhookも障害点を追加します。
Webhookのモデルでは、Kubernetesは外部のサービスを呼び出します。
バイナリプラグイン モデルでは、Kubernetesはバイナリ(プログラム)を実行します。
バイナリプラグインはkubelet(例、FlexVolumeプラグイン、ネットワークプラグイン)、またkubectlで利用されています。
下図は、それぞれの拡張ポイントが、Kubernetesのコントロールプレーンとどのように関わっているかを示しています。
拡張ポイント
この図は、Kubernetesにおける拡張ポイントを示しています。
- ユーザーは頻繁に
kubectlを使って、Kubernetes APIとやり取りをします。Kubectlプラグインは、kubectlのバイナリを拡張します。これは個別ユーザーのローカル環境のみに影響を及ぼすため、サイト全体にポリシーを強制することはできません。
- APIサーバーは全てのリクエストを処理します。APIサーバーのいくつかの拡張ポイントは、リクエストを認可する、コンテキストに基づいてブロックする、リクエストを編集する、そして削除を処理することを可能にします。これらはAPIアクセスエクステンションセクションに記載されています。
- APIサーバーは様々な種類の リソース を扱います。
Podのような ビルトインリソース はKubernetesプロジェクトにより定義され、変更できません。ユーザーも、自身もしくは、他のプロジェクトで定義されたリソースを追加することができます。それは カスタムリソース と呼ばれ、カスタムリソースセクションに記載されています。カスタムリソースは度々、APIアクセスエクステンションと一緒に使われます。
- KubernetesのスケジューラーはPodをどのノードに配置するかを決定します。スケジューリングを拡張するには、いくつかの方法があります。それらはスケジューラーエクステンションセクションに記載されています。
- Kubernetesにおける多くの振る舞いは、APIサーバーのクライアントであるコントローラーと呼ばれるプログラムに実装されています。コントローラーは度々、カスタムリソースと共に使われます。
- kubeletはサーバー上で実行され、Podが仮想サーバーのようにクラスターネットワーク上にIPを持った状態で起動することをサポートします。ネットワークプラグインがPodのネットワーキングにおける異なる実装を適用することを可能にします。
- kubeletはまた、コンテナのためにボリュームをマウント、アンマウントします。新しい種類のストレージはストレージプラグインを通じてサポートされます。
もしあなたがどこから始めるべきかわからない場合、このフローチャートが役立つでしょう。一部のソリューションは、いくつかの種類のエクステンションを含んでいることを留意してください。
APIエクステンション
ユーザー定義タイプ
新しいコントローラー、アプリケーションの設定に関するオブジェクト、また宣言型APIを定義し、それらをkubectlのようなKubernetesのツールから管理したい場合、Kubernetesにカスタムリソースを追加することを検討して下さい。
カスタムリソースはアプリケーション、ユーザー、監視データのデータストレージとしては使わないで下さい。
カスタムリソースに関するさらなる情報は、カスタムリソースコンセプトガイドを参照して下さい。
新しいAPIと自動化機能の連携
カスタムリソースAPIと制御ループの組み合わせはオペレーターパターンと呼ばれています。オペレーターパターンは、通常ステートフルな特定のアプリケーションを管理するために利用されます。これらのカスタムAPIと制御ループは、ストレージ、またはポリシーのような他のリソースを管理するためにも利用されます。
ビルトインリソースの変更
カスタムリソースを追加し、KubernetesAPIを拡張する場合、新たに追加されたリソースは常に新しいAPIグループに分類されます。既存のAPIグループを置き換えたり、変更することはできません。APIを追加することは直接、既存のAPI(例、Pod)の振る舞いに影響を与えることは無いですが、APIアクセスエクステンションの場合、その可能性があります。
APIアクセスエクステンション
リクエストがKubernetes APIサーバーに到達すると、まず最初に認証が行われ、次に認可、その後、様々なAdmission Controlの対象になります。このフローの詳細はKubernetes APIへのアクセスをコントロールするを参照して下さい。
これらの各ステップごとに拡張ポイントが用意されています。
Kubdernetesはいくつかのビルトイン認証方式をサポートしています。それは認証プロキシの後ろに配置することも可能で、認可ヘッダーを通じて(Webhookの)検証のために外部サービスにトークンを送ることもできます。全てのこれらの方法は認証ドキュメントでカバーされています。
認証
認証は、全てのリクエストのヘッダーまたは証明書情報を、リクエストを投げたクライアントのユーザー名にマッピングします。
Kubernetesはいくつかのビルトイン認証方式と、それらが要件に合わない場合、認証Webhookを提供します。
認可
認可は特定のユーザーがAPIリソースに対して、読み込み、書き込み、そしてその他の操作が可能かどうかを決定します。それはオブジェクト全体のレベルで機能し、任意のオブジェクトフィールドに基づいての区別は行いません。もしビルトインの認可メカニズムが要件に合わない場合、認可Webhookが、ユーザー提供のコードを呼び出し認可の決定を行うことを可能にします。
動的Admission Control
リクエストが認可された後、もしそれが書き込み操作だった場合、リクエストはAdmission Controlのステップを通ります。ビルトインのステップに加え、いくつかのエクステンションが存在します:
インフラストラクチャエクステンション
ストレージプラグイン
Flex Volumesは、Kubeletがバイナリプラグインを呼び出してボリュームをマウントすることにより、ユーザーはビルトインのサポートなしでボリュームタイプをマウントすることを可能にします。
デバイスプラグイン
デバイスプラグインを通じて、ノードが新たなノードのリソース(CPU、メモリなどのビルトインのものに加え)を見つけることを可能にします。
ネットワークプラグイン
他のネットワークファブリックがネットワークプラグインを通じてサポートされます。
スケジューラーエクステンション
スケジューラーは特別な種類のコントローラーで、Podを監視し、Podをノードに割り当てます。デフォルトのコントローラーを完全に置き換えることもできますが、他のKubernetesのコンポーネントの利用を継続する、または複数のスケジューラーを同時に動かすこともできます。
これはかなりの大きな作業で、ほとんど全てのKubernetesユーザーはスケジューラーを変更する必要はありません。
スケジューラはWebhookもサポートしており、Webhookバックエンド(スケジューラーエクステンション)を通じてPodを配置するために選択されたノードをフィルタリング、優先度付けすることが可能です。
次の項目
2.1 - カスタムリソース
カスタムリソース はKubernetes APIの拡張です。このページでは、いつKubernetesのクラスターにカスタムリソースを追加するべきなのか、そしていつスタンドアローンのサービスを利用するべきなのかを議論します。カスタムリソースを追加する2つの方法と、それらの選択方法について説明します。
カスタムリソース
リソース は、Kubernetes APIのエンドポイントで、特定のAPIオブジェクトのコレクションを保持します。例えば、ビルトインの Pods リソースは、Podオブジェクトのコレクションを包含しています。
カスタムリソース は、Kubernetes APIの拡張で、デフォルトのKubernetesインストールでは、必ずしも利用できるとは限りません。つまりそれは、特定のKubernetesインストールのカスタマイズを表します。しかし、今現在、多数のKubernetesのコア機能は、カスタムリソースを用いて作られており、Kubernetesをモジュール化しています。
カスタムリソースは、稼働しているクラスターに動的に登録され、現れたり、消えたりし、クラスター管理者はクラスター自体とは無関係にカスタムリソースを更新できます。一度、カスタムリソースがインストールされると、ユーザーはkubectlを使い、ビルトインのリソースである Pods と同じように、オブジェクトを作成、アクセスすることが可能です。
カスタムコントローラー
カスタムリソースそれ自身は、単純に構造化データを格納、取り出す機能を提供します。カスタムリソースを カスタムコントローラー と組み合わせることで、カスタムリソースは真の 宣言的API を提供します。
宣言的APIは、リソースのあるべき状態を 宣言 または指定することを可能にし、Kubernetesオブジェクトの現在の状態を、あるべき状態に同期し続けるように動きます。
コントローラーは、構造化データをユーザーが指定したあるべき状態と解釈し、その状態を管理し続けます。
稼働しているクラスターのライフサイクルとは無関係に、カスタムコントローラーをデプロイ、更新することが可能です。カスタムコントローラーはあらゆるリソースと連携できますが、カスタムリソースと組み合わせると特に効果を発揮します。オペレーターパターンは、カスタムリソースとカスタムコントローラーの組み合わせです。カスタムコントローラーにより、特定アプリケーションのドメイン知識を、Kubernetes APIの拡張に変換することができます。
カスタムリソースをクラスターに追加するべきか?
新しいAPIを作る場合、APIをKubernetesクラスターAPIにアグリゲート(集約)するか、もしくはAPIをスタンドアローンで動かすかを検討します。
| APIアグリゲーションを使う場合: |
スタンドアローンAPIを使う場合: |
| APIが宣言的 |
APIが宣言的モデルに適さない |
新しいリソースをkubectlを使い読み込み、書き込みしたい |
kubectlのサポートは必要ない |
| 新しいリソースをダッシュボードのような、Kubernetes UIで他のビルトインリソースと同じように管理したい |
Kubernetes UIのサポートは必要ない |
| 新しいAPIを開発している |
APIを提供し、適切に機能するプログラムが既に存在している |
| APIグループ、名前空間というような、RESTリソースパスに割り当てられた、Kubernetesのフォーマット仕様の制限を許容できる(API概要を参照) |
既に定義済みのREST APIと互換性を持っていなければならない |
| リソースはクラスターごとか、クラスター内の名前空間に自然に分けることができる |
クラスター、または名前空間による分割がリソース管理に適さない。特定のリソースパスに基づいて管理したい |
| Kubernetes APIサポート機能を再利用したい |
これらの機能は必要ない |
宣言的API
宣言的APIは、通常、下記に該当します:
- APIは、比較的少数の、比較的小さなオブジェクト(リソース)で構成されている
- オブジェクトは、アプリケーションの設定、インフラストラクチャーを定義する
- オブジェクトは、比較的更新頻度が低い
- 人は、オブジェクトの情報をよく読み書きする
- オブジェクトに対する主要な手続きは、CRUD(作成、読み込み、更新、削除)になる
- 複数オブジェクトをまたいだトランザクションは必要ない: APIは今現在の状態ではなく、あるべき状態を表現する
命令的APIは、宣言的ではありません。
APIが宣言的ではない兆候として、次のものがあります:
- クライアントから"これを実行"と命令がきて、完了の返答を同期的に受け取る
- クライアントから"これを実行"と命令がきて、処理IDを取得する。そして処理が完了したかどうかを、処理IDを利用して別途問い合わせる
- リモートプロシージャコール(RPC)という言葉が飛び交っている
- 直接、大量のデータを格納している(例、1オブジェクトあたり数kBより大きい、または数千オブジェクトより多い)
- 高帯域アクセス(持続的に毎秒数十リクエスト)が必要
- エンドユーザーのデータ(画像、PII、その他)を格納している、またはアプリケーションが処理する大量のデータを格納している
- オブジェクトに対する処理が、CRUDではない
- APIをオブジェクトとして簡単に表現できない
- 停止している処理を処理ID、もしくは処理オブジェクトで表現することを選択している
ConfigMapとカスタムリソースのどちらを使うべきか?
下記のいずれかに該当する場合は、ConfigMapを使ってください:
mysql.cnf、pom.xmlのような、十分に文書化された設定ファイルフォーマットが既に存在している- 単一キーのConfigMapに、設定ファイルの内容の全てを格納している
- 設定ファイルの主な用途は、クラスター上のPodで実行されているプログラムがファイルを読み込み、それ自体を構成することである
- ファイルの利用者は、Kubernetes APIよりも、Pod内のファイルまたはPod内の環境変数を介して利用することを好む
- ファイルが更新されたときに、Deploymentなどを介してローリングアップデートを行いたい
備考: センシティブなデータには、ConfigMapに類似していますがよりセキュアな
secretを使ってください
下記のほとんどに該当する場合、カスタムリソース(CRD、またはアグリゲートAPI)を使ってください:
- 新しいリソースを作成、更新するために、Kubernetesのクライアントライブラリー、CLIを使いたい
- kubectlのトップレベルサポートが欲しい(例、
kubectl get my-object object-name)
- 新しい自動化の仕組みを作り、新しいオブジェクトの更新をウォッチしたい、その更新を契機に他のオブジェクトのCRUDを実行したい、またはその逆を行いたい
- オブジェクトの更新を取り扱う、自動化の仕組みを書きたい
.spec、.status、.metadataというような、Kubernetes APIの慣習を使いたい- オブジェクトは、制御されたリソースコレクションの抽象化、または他のリソースのサマリーとしたい
カスタムリソースを追加する
Kubernetesは、クラスターへカスタムリソースを追加する2つの方法を提供しています:
- CRDはシンプルで、プログラミングなしに作成可能
- APIアグリゲーションは、プログラミングが必要だが、データがどのように格納され、APIバージョン間でどのように変換されるかというような、より詳細なAPIの振る舞いを制御できる
Kubernetesは、さまざまなユーザーのニーズを満たすためにこれら2つのオプションを提供しており、使いやすさや柔軟性が損なわれることはありません。
アグリゲートAPIは、プロキシーとして機能するプライマリAPIサーバーの背後にある、下位のAPIServerです。このような配置はAPIアグリゲーション(AA)と呼ばれています。ユーザーにとっては、単にAPIサーバーが拡張されているように見えます。
CRDでは、APIサーバーの追加なしに、ユーザーが新しい種類のリソースを作成できます。CRDを使うには、APIアグリゲーションを理解する必要はありません。
どのようにインストールされたかに関わらず、新しいリソースはカスタムリソースとして参照され、ビルトインのKubernetesリソース(Podなど)とは区別されます。
CustomResourceDefinition
CustomResourceDefinitionAPIリソースは、カスタムリソースを定義します。CRDオブジェクトを定義することで、指定した名前、スキーマで新しいカスタムリソースが作成されます。Kubernetes APIは、作成したカスタムリソースのストレージを提供、および処理します。
CRDオブジェクトの名前はDNSサブドメイン名に従わなければなりません。
これはカスタムリソースを処理するために、独自のAPIサーバーを書くことから解放してくれますが、一般的な性質としてAPIサーバーアグリゲーションと比べると、柔軟性に欠けます。
新しいカスタムリソースをどのように登録するか、新しいリソースタイプとの連携、そしてコントローラーを使いイベントを処理する方法例について、カスタムコントローラー例を参照してください。
APIサーバーアグリゲーション
通常、Kubernetes APIの各リソースは、RESTリクエストとオブジェクトの永続的なストレージを管理するためのコードが必要です。メインのKubernetes APIサーバーは Pod や Service のようなビルトインのリソースを処理し、またカスタムリソースもCRDを通じて同じように管理することができます。
アグリゲーションレイヤーは、独自のAPIサーバーを書き、デプロイすることで、カスタムリソースに特化した実装の提供を可能にします。メインのAPIサーバーが、処理したいカスタムリソースへのリクエストを独自のAPIサーバーに委譲することで、他のクライアントからも利用できるようにします。
カスタムリソースの追加方法を選択する
CRDは簡単に使えます。アグリゲートAPIはより柔軟です。ニーズに最も合う方法を選択してください。
通常、CRDは下記の場合に適しています:
- 少数のフィールドしか必要ない
- そのリソースは社内のみで利用している、または小さいオープンソースプロジェクトの一部で利用している(商用プロダクトではない)
使いやすさの比較
CRDは、アグリゲートAPIと比べ、簡単に作れます。
| CRD |
アグリゲートAPI |
| プログラミングが不要で、ユーザーはCRDコントローラーとしてどの言語でも選択可能 |
Go言語でプログラミングし、バイナリとイメージの作成が必要 |
| 追加のサービスは不要。CRDはAPIサーバーで処理される |
追加のサービス作成が必要で、障害が発生する可能性がある |
| CRDが作成されると、継続的なサポートは無い。バグ修正は通常のKubernetesマスターのアップグレードで行われる |
定期的にアップストリームからバグ修正の取り込み、リビルド、そしてアグリゲートAPIサーバーの更新が必要かもしれない |
| 複数バージョンのAPI管理は不要。例えば、あるリソースを操作するクライアントを管理していた場合、APIのアップグレードと一緒に更新される |
複数バージョンのAPIを管理しなければならない。例えば、世界中に共有されている拡張機能を開発している場合 |
高度な機能、柔軟性
アグリゲートAPIは、例えばストレージレイヤーのカスタマイズのような、より高度なAPI機能と他の機能のカスタマイズを可能にします。
| 機能 |
詳細 |
CRD |
アグリゲートAPI |
| バリデーション |
エラーを予防し、クライアントと無関係にAPIを発達させることができるようになる。これらの機能は多数のクライアントがおり、同時に全てを更新できないときに最も効果を発揮する |
はい、ほとんどのバリデーションはOpenAPI v3.0 validationで、CRDに指定できる。その他のバリデーションはWebhookのバリデーションによりサポートされている |
はい、任意のバリデーションが可能 |
| デフォルト設定 |
上記を参照 |
はい、OpenAPI v3.0 validationのdefaultキーワード(1.17でGA)、またはMutating Webhookを通じて可能 (ただし、この方法は古いオブジェクトをetcdから読み込む場合には動きません) |
はい |
| 複数バージョニング |
同じオブジェクトを、違うAPIバージョンで利用可能にする。フィールドの名前を変更するなどのAPIの変更を簡単に行うのに役立つ。クライアントのバージョンを管理する場合、重要性は下がる |
はい |
はい |
| カスタムストレージ |
異なる性能のストレージが必要な場合(例えば、キーバリューストアの代わりに時系列データベース)または、セキュリティの分離(例えば、機密情報の暗号化、その他) |
いいえ |
はい |
| カスタムビジネスロジック |
オブジェクトが作成、読み込み、更新、また削除されるときに任意のチェック、アクションを実行する |
はい、Webhooksを利用 |
はい |
| サブリソースのスケール |
HorizontalPodAutoscalerやPodDisruptionBudgetなどのシステムが、新しいリソースと連携できるようにする |
はい |
はい |
| サブリソースの状態 |
ユーザーがspecセクションに書き込み、コントローラーがstatusセクションに書き込む際に、より詳細なアクセスコントロールができるようにする。カスタムリソースのデータ変換時にオブジェクトの世代を上げられるようにする(リソース内のspecとstatusでセクションが分離している必要がある) |
はい |
はい |
| その他のサブリソース |
"logs"や"exec"のような、CRUD以外の処理の追加 |
いいえ |
はい |
| strategic-merge-patch |
Content-Type: application/strategic-merge-patch+jsonで、PATCHをサポートする新しいエンドポイント。ローカル、サーバー、どちらでも更新されうるオブジェクトに有用。さらなる情報は"APIオブジェクトをkubectl patchで決まった場所で更新"を参照 |
いいえ |
はい |
| プロトコルバッファ |
プロトコルバッファを使用するクライアントをサポートする新しいリソース |
いいえ |
はい |
| OpenAPIスキーマ |
サーバーから動的に取得できる型のOpenAPI(Swagger)スキーマはあるか、許可されたフィールドのみが設定されるようにすることで、ユーザーはフィールド名のスペルミスから保護されているか、型は強制されているか(言い換えると、「文字列」フィールドに「int」を入れさせない) |
はい、OpenAPI v3.0 validation スキーマがベース(1.16でGA) |
はい |
一般的な機能
CRD、またはアグリゲートAPI、どちらを使ってカスタムリソースを作った場合でも、Kubernetesプラットフォーム外でAPIを実装するのに比べ、多数の機能が提供されます:
| 機能 |
何を実現するか |
| CRUD |
新しいエンドポイントが、HTTP、kubectlを通じて、基本的なCRUD処理をサポート |
| Watch |
新しいエンドポイントが、HTTPを通じて、KubernetesのWatch処理をサポート |
| Discovery |
kubectlやダッシュボードのようなクライアントが、自動的にリソースの一覧表示、個別表示、フィールドの編集処理を提供 |
| json-patch |
新しいエンドポイントがContent-Type: application/json-patch+jsonを用いたPATCHをサポート |
| merge-patch |
新しいエンドポイントがContent-Type: application/merge-patch+jsonを用いたPATCHをサポート |
| HTTPS |
新しいエンドポイントがHTTPSを利用 |
| ビルトイン認証 |
拡張機能へのアクセスに認証のため、コアAPIサーバー(アグリゲーションレイヤー)を利用 |
| ビルトイン認可 |
拡張機能へのアクセスにコアAPIサーバーで使われている認可メカニズムを再利用(例、RBAC) |
| ファイナライザー |
外部リソースの削除が終わるまで、拡張リソースの削除をブロック |
| Admission Webhooks |
拡張リソースの作成/更新/削除処理時に、デフォルト値の設定、バリデーションを実施 |
| UI/CLI 表示 |
kubectl、ダッシュボードで拡張リソースを表示 |
| 未設定 対 空設定 |
クライアントは、フィールドの未設定とゼロ値を区別することができる |
| クライアントライブラリーの生成 |
Kubernetesは、一般的なクライアントライブラリーと、タイプ固有のクライアントライブラリーを生成するツールを提供 |
| ラベルとアノテーション |
ツールがコアリソースとカスタムリソースの編集方法を知っているオブジェクト間で、共通のメタデータを提供 |
カスタムリソースのインストール準備
クラスターにカスタムリソースを追加する前に、いくつか認識しておくべき事項があります。
サードパーティのコードと新しい障害点
CRDを作成しても、勝手に新しい障害点が追加されてしまうことはありませんが(たとえば、サードパーティのコードをAPIサーバーで実行することによって)、パッケージ(たとえば、Chart)またはその他のインストールバンドルには、多くの場合、CRDと新しいカスタムリソースのビジネスロジックを実装するサードパーティコードが入ったDeploymentが含まれます。
アグリゲートAPIサーバーのインストールすると、常に新しいDeploymentが付いてきます。
ストレージ
カスタムリソースは、ConfigMapと同じ方法でストレージの容量を消費します。多数のカスタムリソースを作成すると、APIサーバーのストレージ容量を超えてしまうかもしれません。
アグリゲートAPIサーバーも、メインのAPIサーバーと同じストレージを利用するかもしれません。その場合、同じ問題が発生しえます。
認証、認可、そして監査
CRDでは、APIサーバーのビルトインリソースと同じ認証、認可、そして監査ロギングの仕組みを利用します。
もしRBACを使っている場合、ほとんどのRBACのロールは新しいリソースへのアクセスを許可しません。(クラスター管理者ロール、もしくはワイルドカードで作成されたロールを除く)新しいリソースには、明示的にアクセスを許可する必要があります。多くの場合、CRDおよびアグリゲートAPIには、追加するタイプの新しいロール定義がバンドルされています。
アグリゲートAPIサーバーでは、APIサーバーのビルトインリソースと同じ認証、認可、そして監査の仕組みを使う場合と使わない場合があります。
カスタムリソースへのアクセス
Kubernetesのクライアントライブラリーを使い、カスタムリソースにアクセスすることが可能です。全てのクライアントライブラリーがカスタムリソースをサポートしているわけでは無いですが、Go と Python のライブラリーはサポートしています。
カスタムリソースは、下記のような方法で操作できます:
kubectl- kubernetesの動的クライアント
- 自作のRESTクライアント
- Kubernetesクライアント生成ツールを使い生成したクライアント(生成は高度な作業ですが、一部のプロジェクトは、CRDまたはAAとともにクライアントを提供する場合があります)
次の項目
2.2 - アグリゲーションレイヤーを使ったKubernetes APIの拡張
アグリゲーションレイヤーを使用すると、KubernetesのコアAPIで提供されている機能を超えて、追加のAPIでKubernetesを拡張できます。追加のAPIは、service-catalogのような既製のソリューション、または自分で開発したAPIのいずれかです。
アグリゲーションレイヤーは、カスタムリソースとは異なり、kube-apiserverに新しい種類のオブジェクトを認識させる方法です。
アグリゲーションレイヤー
アグリゲーションレイヤーは、kube-apiserverのプロセス内で動きます。拡張リソースが登録されるまでは、アグリゲーションレイヤーは何もしません。APIを登録するには、ユーザーはKubernetes APIで使われるURLのパスを"要求"した、APIService オブジェクトを追加します。それを追加すると、アグリゲーションレイヤーはAPIパス(例、/apis/myextension.mycompany.io/v1/…)への全てのアクセスを、登録されたAPIServiceにプロキシーします。
APIServiceを実装する最も一般的な方法は、クラスター内で実行されるPodで拡張APIサーバー を実行することです。クラスター内のリソース管理に拡張APIサーバーを使用している場合、拡張APIサーバー("extension-apiserver"とも呼ばれます)は通常、1つ以上のコントローラーとペアになっています。apiserver-builderライブラリは、拡張APIサーバーと関連するコントローラーの両方にスケルトンを提供します。
応答遅延
拡張APIサーバーは、kube-apiserverとの間の低遅延ネットワーキングが必要です。
kube-apiserverとの間を5秒以内に往復するためには、ディスカバリーリクエストが必要です。
拡張APIサーバーがそのレイテンシ要件を達成できない場合は、その要件を満たすように変更することを検討してください。また、kube-apiserverでEnableAggregatedDiscoveryTimeout=false フィーチャーゲートを設定することで、タイムアウト制限を無効にすることができます。この非推奨のフィーチャーゲートは将来のリリースで削除される予定です。
次の項目
3 - オペレーターパターン
オペレーターはカスタムリソースを使用するKubernetesへのソフトウェア拡張です。
オペレーターは、特に制御ループのようなKubernetesが持つ仕組みに準拠しています。
モチベーション
オペレーターパターンはサービス、またはサービス群を管理している運用担当者の主な目的をキャプチャすることが目標です。
特定のアプリケーション、サービスの面倒を見ている運用担当者は、システムがどのように振る舞うべきか、どのようにデプロイをするか、何らかの問題があったときにどのように対応するかについて深い知識を持っています。
Kubernetes上でワークロードを稼働させている人は、しばしば繰り返し可能なタスクを自動化することを好みます。
オペレーターパターンは、Kubernetes自身が提供している機能を超えて、あなたがタスクを自動化するために、どのようにコードを書くかをキャプチャします。
Kubernetesにおけるオペレーター
Kubernetesは自動化のために設計されています。追加の作業、設定無しに、Kubernetesのコア機能によって多数のビルトインされた自動化機能が提供されます。
ワークロードのデプロイおよび稼働を自動化するためにKubernetesを使うことができます。 さらに Kubernetesがそれをどのように行うかの自動化も可能です。
Kubernetesのオペレーターパターンコンセプトは、Kubernetesのソースコードを修正すること無く、一つ以上のカスタムリソースにカスタムコントローラーをリンクすることで、クラスターの振る舞いを拡張することを可能にします。
オペレーターはKubernetes APIのクライアントで、Custom Resourceにとっての、コントローラーのように振る舞います。
オペレーターの例
オペレーターを使い自動化できるいくつかのことは、下記のようなものがあります:
- 必要に応じてアプリケーションをデプロイする
- アプリケーションの状態のバックアップを取得、リストアする
- アプリケーションコードの更新と同時に、例えばデータベーススキーマ、追加の設定修正など必要な変更の対応を行う
- Kubernetes APIをサポートしていないアプリケーションに、サービスを公開してそれらを発見する
- クラスターの回復力をテストするために、全て、または一部分の障害をシミュレートする
- 内部のリーダー選出プロセス無しに、分散アプリケーションのリーダーを選択する
オペレーターをもっと詳しく見るとどのように見えるでしょうか?より詳細な例を示します:
- クラスターに設定可能なSampleDBという名前のカスタムリソース
- オペレーターの、コントローラー部分を含むPodが実行されていることを保証するDeployment
- オペレーターのコードを含んだコンテナイメージ
- 設定されているSampleDBのリソースを見つけるために、コントロールプレーンに問い合わせるコントローラーのコード
- オペレーターのコアは、現実を、設定されているリソースにどのように合わせるかをAPIサーバーに伝えるコードです。
- もし新しいSampleDBを追加した場合、オペレーターは永続化データベースストレージを提供するためにPersistentVolumeClaimsをセットアップし、StatefulSetがSampleDBの起動と、初期設定を担うJobを走らせます
- もしそれを削除した場合、オペレーターはスナップショットを取り、StatefulSetとVolumeも合わせて削除されたことを確認します
- オペレーターは定期的なデータベースのバックアップも管理します。それぞれのSampleDBリソースについて、オペレーターはデータベースに接続可能な、バックアップを取得するPodをいつ作成するかを決定します。これらのPodはデータベース接続の詳細情報、クレデンシャルを保持するConfigMapとSecret、もしくはどちらかに依存するでしょう。
- オペレーターは、管理下のリソースの堅牢な自動化を提供することを目的としているため、補助的な追加コードが必要になるかもしれません。この例では、データベースが古いバージョンで動いているかどうかを確認するコードで、その場合、アップグレードを行うJobをあなたに代わり作成します。
オペレーターのデプロイ
オペレーターをデプロイする最も一般的な方法は、Custom Resource Definitionとそれに関連するコントローラーをクラスターに追加することです。
このコントローラーは通常、あなたがコンテナアプリケーションを動かすのと同じように、コントロールプレーン外で動作します。
例えば、コントローラーをDeploymentとしてクラスター内で動かすことができます。
オペレーターを利用する
一度オペレーターをデプロイすると、そのオペレーターを使って、それ自身が使うリソースの種類を追加、変更、または削除できます。
上記の利用例に従ってオペレーターそのもののためのDeploymentをセットアップし、以下のようなコマンドを実行します:
kubectl get SampleDB # 設定したデータベースを発見します
kubectl edit SampleDB/example-database # 手動でいくつかの設定を変更します
これだけです!オペレーターが変更の適用だけでなく既存のサービスがうまく稼働し続けるように面倒を見てくれます。
自分でオペレーターを書く
必要な振る舞いを実装したオペレーターがエコシステム内に無い場合、自分で作成することができます。
次の項目で、自分でクラウドネイティブオペレーターを作るときに利用できるライブラリやツールのリンクを見つけることができます。
オペレーター(すなわち、コントローラー)はどの言語/ランタイムでも実装でき、Kubernetes APIのクライアントとして機能させることができます。
次の項目