Architecture de Journalisation d'évènements (logging)
La journalisation des évènements systèmes et d'applications peut aider à
comprendre ce qui se passe dans un cluster. Les journaux sont particulièrement
utiles pour débogguer les problèmes et surveiller l'activité du cluster. La
plupart des applications modernes ont un mécanisme de journalisation
d'évènements, et la plupart des environnements d'exécution de conteneurs ont été
conçus pour supporter la journalisation des évènements. La méthode de
journalisation la plus facile et la plus répandue pour des applications
conteneurisées est d'écrire dans les flux de sortie standard et d'erreur
(stdout et stderr).
Malgré cela, la fonctionnalité de journalisation fournie nativement par l'environnement d'exécution de conteneurs n'est pas suffisante comme solution complète de journalisation. Quand un conteneur crashe, quand un Pod est expulsé ou quand un nœud disparaît, il est utile de pouvoir accéder au journal d'événements de l'application. C'est pourquoi les journaux doivent avoir leur propre espace de stockage et un cycle de vie indépendamment des nœuds, Pods ou conteneurs. Ce concept est appelé journalisation des évènements au niveau du cluster (cluster-level-logging). Un backend dédié pour stocker, analyser et faire des requêtes est alors nécessaire. Kubernetes n'offre pas nativement de solution de stockage pour les journaux mais il est possible d'intégrer de nombreuses solutions de journalisation d'évènements dans un cluster Kubernetes.
L'architecture de journalisation des évènements au niveau du cluster est décrite en considérant qu'un backend de journalisation est présent à l'intérieur ou à l'extérieur du cluster. Même sans avoir l'intention de journaliser les évènements au niveau du cluster, il est intéressant de savoir comment les journaux sont conservés et gérés au niveau d'un nœud.
Journalisation simple d'évènements dans Kubernetes
Dans cette section, on va utiliser un exemple simple de journalisation d'évènements avec le flux de sortie standard. Cette démonstration utilise un manifeste pour un Pod avec un seul conteneur qui écrit du texte sur le flux de sortie standard toutes les secondes.

apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Pour lancer ce Pod, utilisez la commande suivante :
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
Le résultat est :
pod/counter created
Pour récupérer les événements du conteneur d'un pod, utilisez la commande
kubectl logs de la manière suivante :
kubectl logs counter
Le résultat est :
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
Utilisez kubectl logs pour récupérer les évènements de l'instanciation
précédente d'un Pod en utilisant l'option --previous quand par exemple le
conteneur a crashé.
Si le Pod a plusieurs conteneurs, il faut spécifier le nom du conteneur dont on
veut récupérer le journal d'évènement. Dans notre exemple le conteneur s'appelle
count donc vous pouvez utiliser kubectl logs counter count. Plus de détails
dans la [documentation de kubectl logs] (/docs/reference/generated/kubectl/kubectl-commands#logs)
Journalisation d'évènements au niveau du nœud
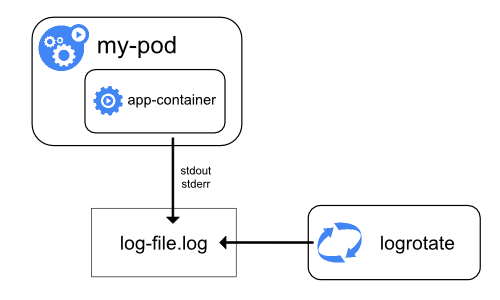
Tout ce qu'une application conteneurisée écrit sur stdout ou stderr est pris
en compte et redirigé par l'environnement d'exécution des conteneurs. Par exemple,
Docker redirige ces deux flux vers un driver de journalisation
(EN) qui est
configuré dans Kubernetes pour écrire dans un fichier au format json.
Par défaut quand un conteneur redémarre, le kubelet ne conserve le journal que du dernier conteneur terminé. Quand un Pod est expulsé d'un nœud, tous ses conteneurs sont aussi expulsés avec leurs journaux d'évènements.
Quand on utilise la journalisation d'évènements au niveau du nœud, il faut prendre garde à mettre en place une politique de rotation des journaux adéquate afin qu'ils n'utilisent pas tout l'espace de stockage du nœud. Kubernetes n'a pas en charge la rotation des journaux, c'est à l'outil de déploiement de le prendre en compte.
Par exemple, dans les clusters Kubernetes déployés avec le script kube-up.sh
logrotate est configuré pour
s'exécuter toutes les heures. Il est aussi possible de configurer
l'environnement d'exécution des conteneurs pour que la rotation des journaux
s'exécute automatiquement, e.g. en utilisant le paramètre log-opt de Docker.
Dans le script kube-up.sh, c'est cette méthode qui est utilisée pour des
images COS sur GCP et sinon c'est la première méthode dans tous les autres cas.
Quelle que soit la méthode choisie par kube-up.sh la rotation est configurée par
défaut quand la taille d'un journal atteint 10 Mo.
Ce script montre de manière détaillée comment kube-up.sh
met en place la journalisation d'évènements pour des images COS sur GCP.
Quand kubectl logs
s'exécute comme dans le premier exemple de journalisation simple le kubelet du
nœud gère la requête et lit directement depuis le fichier de journal et retourne
son contenu dans la réponse.
kubectl logs. Par
exemple quand le journal atteint 10 Mo, logrotate effectue une rotation, il y a
alors 2 fichers, un de 10 Mo et un de vide, à ce moment là kubectl logs
retournera une réponse vide.
Journalisation des évènements des composants système
Il y a deux types de composants système selon qu'ils s'exécutent dans un conteneur ou pas.
Par exemple :
- Le scheduler Kubernetes et kube-proxy s'exécutent dans un conteneur.
- Kubelet et l'environnement d'exécution de conteneurs, comme par exemple Docker, ne s'exécutent pas dans un conteneur.
Sur les systèmes avec systemd, kubelet et l'environnement d'exécution de
conteneurs écrivent dans journald. Si systemd n'est pas présent, ils écrivent
dans un fichier .log dans le répertoire /var/log.
Les composants système qui s'exécutent dans un conteneur écrivent toujours dans
le répertoire /var/log, en contournant le mécanisme de journalisation par
défaut. Ils utilisent la bibliothèque de journalisation klog. Les
conventions pour la sévérité des évènements pour ces composants se trouvent dans
cette [documentation sur les conventions de journalisation des évènements dans
kubernetes]
(https://github.com/kubernetes/community/blob/master/contributors/devel/sig-instrumentation/logging.md).
De la même manière que les journaux des conteneurs, les journaux des composants
systèmes doivent avoir une politique de rotation. Dans un cluster créé avec
le script kube-up.sh, les journaux ont une rotation journalière ou quand leur
taille atteint 100 Mo.
Architecture de journalisation des évènements au niveau du cluster
Kubernetes ne fournit pas de solution native pour la journalisation des évènements au niveau du cluster. Mais il y a différentes approches qui peuvent être considérées :
- Utiliser un agent de journalisation au niveau du nœud sur chacun des nœuds.
- Inclure un conteneur side-car pour journaliser les évènements du Pod applicatif.
- Envoyer les évènements directement a un backend depuis l'application.
Utiliser un agent de journalisation au niveau du nœud
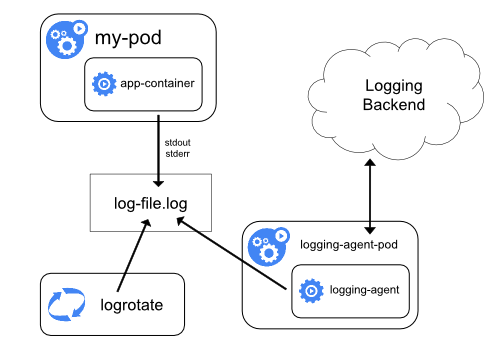
Vous pouvez implémenter une journalisation au niveau du cluster en incluant un agent de journalisation au niveau du nœud sur chacun des nœuds. L'agent de journalisation est un outil dédié qui met à disposition ou envoie les journaux à un backend. Communément l'agent de journalisation est un conteneur qui a accès au répertoire qui contient les journaux des conteneurs applicatifs sur ce nœud.
Comme l'agent de journalisation doit s'exécuter sur chacun des nœuds, on utilise soit un DaemonSet, soit un manifeste de Pod, soit un processus dédié natif sur le nœud. Ces deux dernières options sont obsolètes et fortement découragées.
Utiliser un agent de journalisation au niveau du nœud est l'approche la plus commune et recommandée pour un cluster Kubernetes parce qu'un seul agent par nœud est créé et qu'aucune modification dans l'application n'est nécessaire. Mais cette approche ne fonctionne correctement que pour les flux standards de sortie et d'erreurs des applications.
Kubernetes ne définit pas d'agent de journalisation, mais deux agents de journalisation optionnels sont fournis avec la version de Kubernetes : Stackdriver (EN) pour utiliser sur Google Cloud Platform, et Elasticsearch (EN). Les deux utilisent fluentd avec une configuration spécifique comme agent sur le nœud. Les liens précédents fournissent plus d'informations et les instructions pour les utiliser et configurer.
Inclure un conteneur side-car pour journaliser les évènements du Pod applicatif
Vous pouvez utiliser un conteneur side-car d'une des manières suivantes :
- Le conteneur side-car diffuse les journaux de l'application sur son propre
stdout. - Le conteneur side-car exécute un agent de journalisation qui est configuré pour récupérer les journaux du conteneur applicatif.
Conteneur side-car diffusant (Streaming sidecar container)
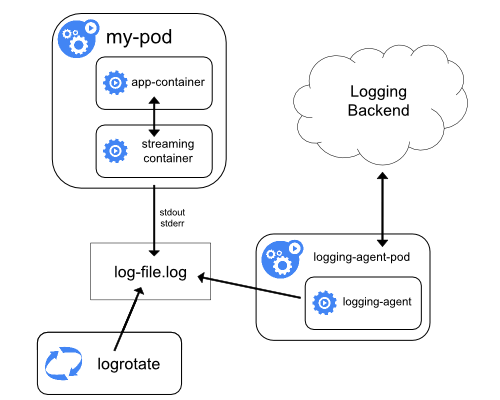
Comme le conteneur side-car diffuse les journaux sur ses propres flux stdout
et stderr, on peut bénéficier du kubelet et de l'agent de journalisation qui
s'exécute déjà sur chaque nœud. Les conteneurs side-car lisent les journaux
depuis un fichier, un socket ou bien journald. Chaque conteneur side-car écrit
son journal sur son propre flux stdout ou stderr.
Cette méthode permet de séparer les flux de journaux de différentes
parties de votre application même si elles ne supportent pas d'écrire sur
stdout ou stderr. La logique de rediriger les journaux est minime et
le surcoût est non significatif. De plus comme les flux standards stdout et
stderr sont gérés par kubelet, les outils natifs comme kubectl logs peuvent
être utilisés.
Regardez l'exemple qui suit.
Un Pod exécute un unique conteneur et ce conteneur écrit dans deux fichiers de journaux différents en utilisant deux format différents. Voici le manifeste du Pod :
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Il serait très désordonné d'avoir des évènements avec des formats différents
dans le même journal en redirigeant les évènements dans le flux de sortie
stdout d'un seul conteneur. Il est plutôt souhaitable d'utiliser deux
conteneurs side-car, un pour chaque type de journaux. Chaque conteneur side-car
suit un des fichiers et renvoie les évènements sur son propre stdout.
Ci-dessous se trouve le manifeste pour un Pod avec deux conteneurs side-car.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Quand ce Pod s'exécute, chaque journal peut être diffusé séparément en utilisant les commandes suivantes :
kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
L'agent au niveau du nœud installé dans le cluster récupère les deux flux de journaux sans aucune configuration supplémentaire. Il est possible de configurer l'agent pour qu'il analyse syntaxiquement les évènements en fonction du conteneur source.
Notez que bien que la consommation en CPU et mémoire soit faible ( de l'ordre de
quelques milicores pour la CPU et quelques mégaoctets pour la mémoire), ecrire
les évènements dans un fichier et les envoyer ensuite dans stdout peut doubler
l'espace disque utilisé. Quand une application écrit dans un seul fichier de
journal, il est préférable de configurer /dev/stdout comme destination plutôt
que d'implémenter un conteneur side-car diffusant.
Les conteneurs side-car peuvent être utilisés pour faire la rotation des
journaux quand l'application n'en est pas capable elle-même. Un exemple serait
un petit conteneur side-car qui effectuerait cette rotation périodiquement.
Toutefois, il est recommandé d'utiliser stdout et stderr directement et de
laisser la rotation et les politiques de rétentions au kubelet.
Conteneur side-car avec un agent de journalisation
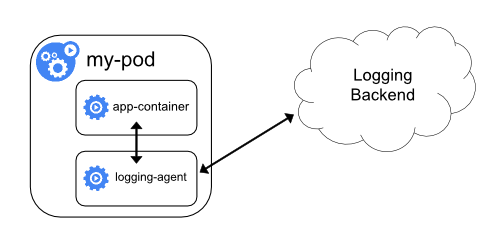
Quand un agent de journalisation au niveau du nœud n'est pas assez flexible pour votre utilisation, vous pouvez créer un conteneur side-car avec un agent de journalisation séparé que vous avez configuré spécialement pour qu'il s'exécute avec votre application.
kubectl parce qu'ils ne sont plus gérés par
kubelet.
Comme exemple, vous pouvez utiliser Stackdriver où fluentd est l'agent de journalisation. Ci-dessous se trouvent deux configurations qui implémentent cette méthode.
Le premier fichier contient un ConfigMap pour configurer fluentd.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Le second fichier est un manifeste pour un Pod avec un conteneur side-car qui exécute fluentd. Le Pod monte un volume où fluentd peut récupérer sa configuration.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Apres quelques minutes, les évènements apparaîtront dans l'interface de Stackdriver.
Ce n'est qu'un exemple et vous pouvez remplacer fluentd par n'importe quel agent de journalisation qui lit depuis n'importe quelle source de votre application.
Envoyer les évènements directement depuis l'application.
Vous pouvez implémenter la journalisation au niveau cluster en mettant à disposition ou en envoyant les journaux directement depuis chaque application; Toutefois l'implémentation de ce mécanisme de journalisation est hors du cadre de Kubernetes.