This article is more than one year old. Older articles may contain outdated content. Check that the information in the page has not become incorrect since its publication.
Kubernetes Topology Manager Moves to Beta - Align Up!
Authors: Kevin Klues (NVIDIA), Victor Pickard (Red Hat), Conor Nolan (Intel)
This blog post describes the TopologyManager, a beta feature of Kubernetes in release 1.18. The TopologyManager feature enables NUMA alignment of CPUs and peripheral devices (such as SR-IOV VFs and GPUs), allowing your workload to run in an environment optimized for low-latency.
Prior to the introduction of the TopologyManager, the CPU and Device Manager would make resource allocation decisions independent of each other. This could result in undesirable allocations on multi-socket systems, causing degraded performance on latency critical applications. With the introduction of the TopologyManager, we now have a way to avoid this.
This blog post covers:
- A brief introduction to NUMA and why it is important
- The policies available to end-users to ensure NUMA alignment of CPUs and devices
- The internal details of how the
TopologyManagerworks - Current limitations of the
TopologyManager - Future directions of the
TopologyManager
So, what is NUMA and why do I care?
The term NUMA stands for Non-Uniform Memory Access. It is a technology available on multi-cpu systems that allows different CPUs to access different parts of memory at different speeds. Any memory directly connected to a CPU is considered "local" to that CPU and can be accessed very fast. Any memory not directly connected to a CPU is considered "non-local" and will have variable access times depending on how many interconnects must be passed through in order to reach it. On modern systems, the idea of having "local" vs. "non-local" memory can also be extended to peripheral devices such as NICs or GPUs. For high performance, CPUs and devices should be allocated such that they have access to the same local memory.
All memory on a NUMA system is divided into a set of "NUMA nodes", with each node representing the local memory for a set of CPUs or devices. We talk about an individual CPU as being part of a NUMA node if its local memory is associated with that NUMA node.
We talk about a peripheral device as being part of a NUMA node based on the shortest number of interconnects that must be passed through in order to reach it.
For example, in Figure 1, CPUs 0-3 are said to be part of NUMA node 0, whereas CPUs 4-7 are part of NUMA node 1. Likewise GPU 0 and NIC 0 are said to be part of NUMA node 0 because they are attached to Socket 0, whose CPUs are all part of NUMA node 0. The same is true for GPU 1 and NIC 1 on NUMA node 1.
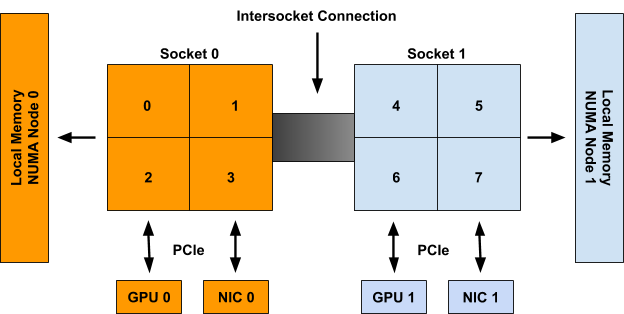
Figure 1: An example system with 2 NUMA nodes, 2 Sockets with 4 CPUs each, 2 GPUs, and 2 NICs. CPUs on Socket 0, GPU 0, and NIC 0 are all part of NUMA node 0. CPUs on Socket 1, GPU 1, and NIC 1 are all part of NUMA node 1.
Although the example above shows a 1-1 mapping of NUMA Node to Socket, this is not necessarily true in the general case. There may be multiple sockets on a single NUMA node, or individual CPUs of a single socket may be connected to different NUMA nodes. Moreover, emerging technologies such as Sub-NUMA Clustering (available on recent intel CPUs) allow single CPUs to be associated with multiple NUMA nodes so long as their memory access times to both nodes are the same (or have a negligible difference).
The TopologyManager has been built to handle all of these scenarios.
Align Up! It's a TeaM Effort!
As previously stated, the TopologyManager allows users to align their CPU and peripheral device allocations by NUMA node. There are several policies available for this:
none:this policy will not attempt to do any alignment of resources. It will act the same as if theTopologyManagerwere not present at all. This is the default policy.best-effort:with this policy, theTopologyManagerwill attempt to align allocations on NUMA nodes as best it can, but will always allow the pod to start even if some of the allocated resources are not aligned on the same NUMA node.restricted:this policy is the same as thebest-effortpolicy, except it will fail pod admission if allocated resources cannot be aligned properly. Unlike with thesingle-numa-nodepolicy, some allocations may come from multiple NUMA nodes if it is impossible to ever satisfy the allocation request on a single NUMA node (e.g. 2 devices are requested and the only 2 devices on the system are on different NUMA nodes).single-numa-node:this policy is the most restrictive and will only allow a pod to be admitted if all requested CPUs and devices can be allocated from exactly one NUMA node.
It is important to note that the selected policy is applied to each container in a pod spec individually, rather than aligning resources across all containers together.
Moreover, a single policy is applied to all pods on a node via a global kubelet flag, rather than allowing users to select different policies on a pod-by-pod basis (or a container-by-container basis). We hope to relax this restriction in the future.
The kubelet flag to set one of these policies can be seen below:
--topology-manager-policy=
[none | best-effort | restricted | single-numa-node]
Additionally, the TopologyManager is protected by a feature gate. This feature gate has been available since Kubernetes 1.16, but has only been enabled by default since 1.18.
The feature gate can be enabled or disabled as follows (as described in more detail here):
--feature-gates="...,TopologyManager=<true|false>"
In order to trigger alignment according to the selected policy, a user must request CPUs and peripheral devices in their pod spec, according to a certain set of requirements.
For peripheral devices, this means requesting devices from the available resources provided by a device plugin (e.g. intel.com/sriov, nvidia.com/gpu, etc.). This will only work if the device plugin has been extended to integrate properly with the TopologyManager. Currently, the only plugins known to have this extension are the Nvidia GPU device plugin, and the Intel SRIOV network device plugin. Details on how to extend a device plugin to integrate with the TopologyManager can be found here.
For CPUs, this requires that the CPUManager has been configured with its --static policy enabled and that the pod is running in the Guaranteed QoS class (i.e. all CPU and memory limits are equal to their respective CPU and memory requests). CPUs must also be requested in whole number values (e.g. 1, 2, 1000m, etc). Details on how to set the CPUManager policy can be found here.
For example, assuming the CPUManager is running with its --static policy enabled and the device plugins for gpu-vendor.com, and nic-vendor.com have been extended to integrate with the TopologyManager properly, the pod spec below is sufficient to trigger the TopologyManager to run its selected policy:
spec:
containers:
- name: numa-aligned-container
image: alpine
resources:
limits:
cpu: 2
memory: 200Mi
gpu-vendor.com/gpu: 1
nic-vendor.com/nic: 1
Following Figure 1 from the previous section, this would result in one of the following aligned allocations:
{cpu: {0, 1}, gpu: 0, nic: 0}
{cpu: {0, 2}, gpu: 0, nic: 0}
{cpu: {0, 3}, gpu: 0, nic: 0}
{cpu: {1, 2}, gpu: 0, nic: 0}
{cpu: {1, 3}, gpu: 0, nic: 0}
{cpu: {2, 3}, gpu: 0, nic: 0}
{cpu: {4, 5}, gpu: 1, nic: 1}
{cpu: {4, 6}, gpu: 1, nic: 1}
{cpu: {4, 7}, gpu: 1, nic: 1}
{cpu: {5, 6}, gpu: 1, nic: 1}
{cpu: {5, 7}, gpu: 1, nic: 1}
{cpu: {6, 7}, gpu: 1, nic: 1}
And that’s it! Just follow this pattern to have the TopologyManager ensure NUMA alignment across containers that request topology-aware devices and exclusive CPUs.
**NOTE:** if a pod is rejected by one of the **TopologyManager** policies, it will be placed in a **Terminated** state with a pod admission error and a reason of "TopologyAffinityError". Once a pod is in this state, the Kubernetes scheduler will not attempt to reschedule it. It is therefore recommended to use a Deployment with replicas to trigger a redeploy of the pod on such a failure. An external control loop can also be implemented to trigger a redeployment of pods that have a TopologyAffinityError.
This is great, so how does it work under the hood?
Pseudocode for the primary logic carried out by the TopologyManager can be seen below:
for container := range append(InitContainers, Containers...) {
for provider := range HintProviders {
hints += provider.GetTopologyHints(container)
}
bestHint := policy.Merge(hints)
for provider := range HintProviders {
provider.Allocate(container, bestHint)
}
}
The following diagram summarizes the steps taken during this loop:
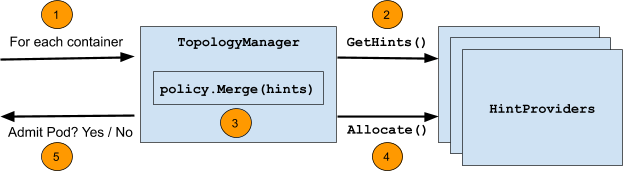
The steps themselves are:
- Loop over all containers in a pod.
- For each container, gather "
TopologyHints" from a set of "HintProviders" for each topology-aware resource type requested by the container (e.g.gpu-vendor.com/gpu,nic-vendor.com/nic,cpu, etc.). - Using the selected policy, merge the gathered
TopologyHintsto find the "best" hint that aligns resource allocations across all resource types. - Loop back over the set of hint providers, instructing them to allocate the resources they control using the merged hint as a guide.
- This loop runs at pod admission time and will fail to admit the pod if any of these steps fail or alignment cannot be satisfied according to the selected policy. Any resources allocated before the failure are cleaned up accordingly.
The following sections go into more detail on the exact structure of TopologyHints and HintProviders, as well as some details on the merge strategies used by each policy.
TopologyHints
A TopologyHint encodes a set of constraints from which a given resource request can be satisfied. At present, the only constraint we consider is NUMA alignment. It is defined as follows:
type TopologyHint struct {
NUMANodeAffinity bitmask.BitMask
Preferred bool
}
The NUMANodeAffinity field contains a bitmask of NUMA nodes where a resource request can be satisfied. For example, the possible masks on a system with 2 NUMA nodes include:
{00}, {01}, {10}, {11}
The Preferred field contains a boolean that encodes whether the given hint is "preferred" or not. With the best-effort policy, preferred hints will be given preference over non-preferred hints when generating a "best" hint. With the restricted and single-numa-node policies, non-preferred hints will be rejected.
In general, HintProviders generate TopologyHints by looking at the set of currently available resources that can satisfy a resource request. More specifically, they generate one TopologyHint for every possible mask of NUMA nodes where that resource request can be satisfied. If a mask cannot satisfy the request, it is omitted. For example, a HintProvider might provide the following hints on a system with 2 NUMA nodes when being asked to allocate 2 resources. These hints encode that both resources could either come from a single NUMA node (either 0 or 1), or they could each come from different NUMA nodes (but we prefer for them to come from just one).
{01: True}, {10: True}, {11: False}
At present, all HintProviders set the Preferred field to True if and only if the NUMANodeAffinity encodes a minimal set of NUMA nodes that can satisfy the resource request. Normally, this will only be True for TopologyHints with a single NUMA node set in their bitmask. However, it may also be True if the only way to ever satisfy the resource request is to span multiple NUMA nodes (e.g. 2 devices are requested and the only 2 devices on the system are on different NUMA nodes):
{0011: True}, {0111: False}, {1011: False}, {1111: False}
NOTE: Setting of the Preferred field in this way is not based on the set of currently available resources. It is based on the ability to physically allocate the number of requested resources on some minimal set of NUMA nodes.
In this way, it is possible for a HintProvider to return a list of hints with all Preferred fields set to False if an actual preferred allocation cannot be satisfied until other containers release their resources. For example, consider the following scenario from the system in Figure 1:
- All but 2 CPUs are currently allocated to containers
- The 2 remaining CPUs are on different NUMA nodes
- A new container comes along asking for 2 CPUs
In this case, the only generated hint would be {11: False} and not {11: True}. This happens because it is possible to allocate 2 CPUs from the same NUMA node on this system (just not right now, given the current allocation state). The idea being that it is better to fail pod admission and retry the deployment when the minimal alignment can be satisfied than to allow a pod to be scheduled with sub-optimal alignment.
HintProviders
A HintProvider is a component internal to the kubelet that coordinates aligned resource allocations with the TopologyManager. At present, the only HintProviders in Kubernetes are the CPUManager and the DeviceManager. We plan to add support for HugePages soon.
As discussed previously, the TopologyManager both gathers TopologyHints from HintProviders as well as triggers aligned resource allocations on them using a merged "best" hint. As such, HintProviders implement the following interface:
type HintProvider interface {
GetTopologyHints(*v1.Pod, *v1.Container) map[string][]TopologyHint
Allocate(*v1.Pod, *v1.Container) error
}
Notice that the call to GetTopologyHints() returns a map[string][]TopologyHint. This allows a single HintProvider to provide hints for multiple resource types instead of just one. For example, the DeviceManager requires this in order to pass hints back for every resource type registered by its plugins.
As HintProviders generate their hints, they only consider how alignment could be satisfied for currently available resources on the system. Any resources already allocated to other containers are not considered.
For example, consider the system in Figure 1, with the following two containers requesting resources from it:
Container0
|
Container1
|
spec:
containers:
- name: numa-aligned-container0
image: alpine
resources:
limits:
cpu: 2
memory: 200Mi
gpu-vendor.com/gpu: 1
nic-vendor.com/nic: 1
|
spec:
containers:
- name: numa-aligned-container1
image: alpine
resources:
limits:
cpu: 2
memory: 200Mi
gpu-vendor.com/gpu: 1
nic-vendor.com/nic: 1
|
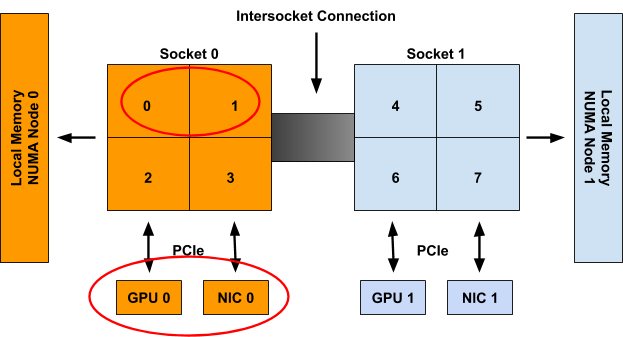
If Container0 is the first container considered for allocation on the system, the following set of hints will be generated for the three topology-aware resource types in the spec.
cpu: {{01: True}, {10: True}, {11: False}}
gpu-vendor.com/gpu: {{01: True}, {10: True}}
nic-vendor.com/nic: {{01: True}, {10: True}}
With a resulting aligned allocation of:
{cpu: {0, 1}, gpu: 0, nic: 0}
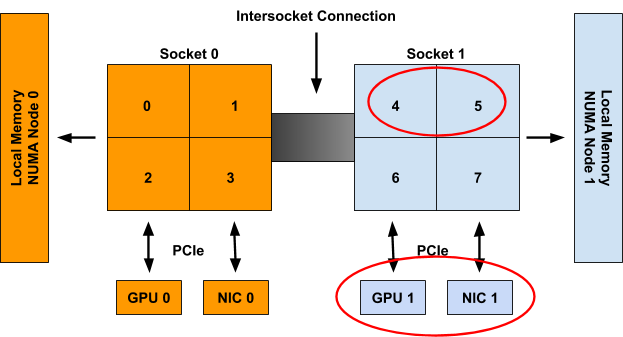
When considering Container1 these resources are then presumed to be unavailable, and thus only the following set of hints will be generated:
cpu: {{01: True}, {10: True}, {11: False}}
gpu-vendor.com/gpu: {{10: True}}
nic-vendor.com/nic: {{10: True}}
With a resulting aligned allocation of:
{cpu: {4, 5}, gpu: 1, nic: 1}
NOTE: Unlike the pseudocode provided at the beginning of this section, the call to Allocate() does not actually take a parameter for the merged "best" hint directly. Instead, the TopologyManager implements the following Store interface that HintProviders can query to retrieve the hint generated for a particular container once it has been generated:
type Store interface {
GetAffinity(podUID string, containerName string) TopologyHint
}
Separating this out into its own API call allows one to access this hint outside of the pod admission loop. This is useful for debugging as well as for reporting generated hints in tools such as kubectl(not yet available).
Policy.Merge
The merge strategy defined by a given policy dictates how it combines the set of TopologyHints generated by all HintProviders into a single TopologyHint that can be used to inform aligned resource allocations.
The general merge strategy for all supported policies begins the same:
- Take the cross-product of
TopologyHintsgenerated for each resource type - For each entry in the cross-product,
bitwise-andthe NUMA affinities of eachTopologyHinttogether. Set this as the NUMA affinity in a resulting "merged" hint. - If all of the hints in an entry have
Preferredset toTrue, setPreferredtoTruein the resulting "merged" hint. - If even one of the hints in an entry has
Preferredset toFalse, setPreferredtoFalsein the resulting "merged" hint. Also setPreferredtoFalsein the "merged" hint if its NUMA affinity contains all 0s.
Following the example from the previous section with hints for Container0 generated as:
cpu: {{01: True}, {10: True}, {11: False}}
gpu-vendor.com/gpu: {{01: True}, {10: True}}
nic-vendor.com/nic: {{01: True}, {10: True}}
The above algorithm results in the following set of cross-product entries and "merged" hints:
| cross-product entry
|
"merged" hint |
{{01: True}, {01: True}, {01: True}}
|
{01: True}
|
{{01: True}, {01: True}, {10: True}}
|
{00: False}
|
{{01: True}, {10: True}, {01: True}}
|
{00: False}
|
{{01: True}, {10: True}, {10: True}}
|
{00: False}
|
{{10: True}, {01: True}, {01: True}}
|
{00: False}
|
{{10: True}, {01: True}, {10: True}}
|
{00: False}
|
{{10: True}, {10: True}, {01: True}}
|
{00: False}
|
{{10: True}, {10: True}, {10: True}}
|
{01: True}
|
{{11: False}, {01: True}, {01: True}}
|
{01: False}
|
{{11: False}, {01: True}, {10: True}}
|
{00: False}
|
{{11: False}, {10: True}, {01: True}}
|
{00: False}
|
{{11: False}, {10: True}, {10: True}}
|
{10: False}
|
Once this list of "merged" hints has been generated, it is the job of the specific TopologyManager policy in use to decide which one to consider as the "best" hint.
In general, this involves:
- Sorting merged hints by their "narrowness". Narrowness is defined as the number of bits set in a hint’s NUMA affinity mask. The fewer bits set, the narrower the hint. For hints that have the same number of bits set in their NUMA affinity mask, the hint with the most low order bits set is considered narrower.
- Sorting merged hints by their
Preferredfield. Hints that havePreferredset toTrueare considered more likely candidates than hints withPreferredset toFalse. - Selecting the narrowest hint with the best possible setting for
Preferred.
In the case of the best-effort policy this algorithm will always result in some hint being selected as the "best" hint and the pod being admitted. This "best" hint is then made available to HintProviders so they can make their resource allocations based on it.
However, in the case of the restricted and single-numa-node policies, any selected hint with Preferred set to False will be rejected immediately, causing pod admission to fail and no resources to be allocated. Moreover, the single-numa-node will also reject a selected hint that has more than one NUMA node set in its affinity mask.
In the example above, the pod would be admitted by all policies with a hint of {01: True}.
Upcoming enhancements
While the 1.18 release and promotion to Beta brings along some great enhancements and fixes, there are still a number of limitations, described here. We are already underway working to address these limitations and more.
This section walks through the set of enhancements we plan to implement for the TopologyManager in the near future. This list is not exhaustive, but it gives a good idea of the direction we are moving in. It is ordered by the timeframe in which we expect to see each enhancement completed.
If you would like to get involved in helping with any of these enhancements, please join the weekly Kubernetes SIG-node meetings to learn more and become part of the community effort!
Supporting device-specific constraints
Currently, NUMA affinity is the only constraint considered by the TopologyManager for resource alignment. Moreover, the only scalable extensions that can be made to a TopologyHint involve node-level constraints, such as PCIe bus alignment across device types. It would be intractable to try and add any device-specific constraints to this struct (e.g. the internal NVLINK topology among a set of GPU devices).
As such, we propose an extension to the device plugin interface that will allow a plugin to state its topology-aware allocation preferences, without having to expose any device-specific topology information to the kubelet. In this way, the TopologyManager can be restricted to only deal with common node-level topology constraints, while still having a way of incorporating device-specific topology constraints into its allocation decisions.
Details of this proposal can be found here, and should be available as soon as Kubernetes 1.19.
NUMA alignment for hugepages
As stated previously, the only two HintProviders currently available to the TopologyManager are the CPUManager and the DeviceManager. However, work is currently underway to add support for hugepages as well. With the completion of this work, the TopologyManager will finally be able to allocate memory, hugepages, CPUs and PCI devices all on the same NUMA node.
A KEP for this work is currently under review, and a prototype is underway to get this feature implemented very soon.
Scheduler awareness
Currently, the TopologyManager acts as a Pod Admission controller. It is not directly involved in the scheduling decision of where a pod will be placed. Rather, when the kubernetes scheduler (or whatever scheduler is running in the deployment), places a pod on a node to run, the TopologyManager will decide if the pod should be "admitted" or "rejected". If the pod is rejected due to lack of available NUMA aligned resources, things can get a little interesting. This kubernetes issue highlights and discusses this situation well.
So how do we go about addressing this limitation? We have the Kubernetes Scheduling Framework to the rescue! This framework provides a new set of plugin APIs that integrate with the existing Kubernetes Scheduler and allow scheduling features, such as NUMA alignment, to be implemented without having to resort to other, perhaps less appealing alternatives, including writing your own scheduler, or even worse, creating a fork to add your own scheduler secret sauce.
The details of how to implement these extensions for integration with the TopologyManager have not yet been worked out. We still need to answer questions like:
- Will we require duplicated logic to determine device affinity in the
TopologyManagerand the scheduler? - Do we need a new API to get
TopologyHintsfrom theTopologyManagerto the scheduler plugin?
Work on this feature should begin in the next couple of months, so stay tuned!
Per-pod alignment policy
As stated previously, a single policy is applied to all pods on a node via a global kubelet flag, rather than allowing users to select different policies on a pod-by-pod basis (or a container-by-container basis).
While we agree that this would be a great feature to have, there are quite a few hurdles that need to be overcome before it is achievable. The biggest hurdle being that this enhancement will require an API change to be able to express the desired alignment policy in either the Pod spec or its associated RuntimeClass.
We are only now starting to have serious discussions around this feature, and it is still a few releases away, at the best, from being available.
Conclusion
With the promotion of the TopologyManager to Beta in 1.18, we encourage everyone to give it a try and look forward to any feedback you may have. Many fixes and enhancements have been worked on in the past several releases, greatly improving the functionality and reliability of the TopologyManager and its HintProviders. While there are still a number of limitations, we have a set of enhancements planned to address them, and look forward to providing you with a number of new features in upcoming releases.
If you have ideas for additional enhancements or a desire for certain features, don’t hesitate to let us know. The team is always open to suggestions to enhance and improve the TopologyManager.
We hope you have found this blog informative and useful! Let us know if you have any questions or comments. And, happy deploying…..Align Up!